בפוסט הקודם על קוברנטיס, הגדרנו Pod – יחידת ההרצה הקטנה ביותר בקוברנטיס.
סיימנו בכך ש Pod שנוצר בגפו, מה שקרוי ״Naked Pod״ – ואיננו בעל שרידות גבוהה: אם הוא קרס, או ה node שבו הוא רץ קרס / נסגר – קוברנטיס לא יחדש אותו.
בפוסט הזה נציג סמנטיקה מרכזית נוספת בעבודה עם קוברנטיס: ה Deployment – המכמיסה בתוכה סמנטיקה בשם ReplicaSet אותה נסביר גם כן. הסמנטיקות הללו הן מה שמאפשרות להגדיר/לעדכן pods כך שיהיו resilient. זוהי תכונה קריטית שאנו מקבלים מקוברנטיס, ולא היינו מקבלים מ Dokcer לבדו.
בואו נתחיל.
Resilient Pods
בכדי ליהנות מיכולת מתקדמות של קוברנטיס כגון Self-Healing ו Auto-Scaling – עלינו להימנע מהגדרה של naked pods, ולהשתמש בסמנטיקה בשם ReplicaSet.
ReplicaSet הוא המקבילה של AWS Auto-Scaling-Group, מנגנון המוודא שמספר ה Pods שרצים:
לא יורד ממספר מסוים (Auto-Healing)
עולה בצורה דינאמית כאשר יש עומס על ה Pods (למשל: CPU utilization מעל 60%) – עד גבול מסוים שהגדרנו, ויורד בחזרה – כאשר העומס חולף.
למי שעבד עם שירותי-ענן, הצורך הזה אמור להיות ברור כשמש.
בעבודה עם קוברנטיס, אנחנו לא נעבוד בד"כ עם ReplicaSet, אלא עם סמנטיקה גבוהה יותר בשם Deployment.
Deployment היא בעצם הסמנטיקה לעבוד איתה.
תרשים קונספטואלי ולא מדויק. נדייק אותו בהמשך.
מה Deployment מוסיף על ReplicaSet? במחשבה ראשונה נשמע שאנו זקוקים רק ל ReplicaSet.
ובכן, בואו ניקח תסריט מאוד נפוץ ויומיומי: עדכון Pod לגרסה חדשה יותר. ביצענו שינוי במיקרו-שירות הרץ כ Pod, ואנו רוצים לעדכן את הקוד שלו.
כפי שאנחנו זוכרים, צורת העבודה (המומלצת) עם קוברנטיס היא הגדרה דקלרטיבית:
אנו מגדירים מצב רצוי
קוברנטיס דוגם כל הזמן את המצב המערכת, ואם יש פעם בין המצב הנוכחי למצב הרצוי – היא פועלת לסגירת הפער.
נניח שיש לנו 3 Pod replicas של מיקרו-שירות, הרצים כולם בגרסה 11 (למשל: build number). אנו רוצים לעדכן אותם לגרסה 12.
אם פשוט נעדכן את קוברניס שאנו רוצים את ה Pod replicas בגרסה 12, עלול לקרות המקרה המאוד-לא-רצוי הבא:
קוברנטיס רואה שלא רוצים יותר את גרסה 11 – הוא מכבה את כל ה Pod replicas בגרסה הזו.
לא טוב! מרגע זה אנחנו ב downtime.
קוברנטיס רואה שרוצים את גרסה 12 – הוא מתחיל להריץ Pod replicas של הגרסה הזו.
אבוי! בגרסה 12 יש באג בקוד, והמיקרו-שירות לא מצליח לרוץ.
קוברנטיס יוצר Log מפורט וברור של הבעיה – אבל עד שלא נטפל בה בעצמנו – אנחנו ב Full Downtime.
זה בהחלט לא תסריט שאנו רוצים שיהיה אפשרי בסביבת Production!
Deployment, לשמחתנו, מוסיף את היכולות / האחריות הבאה:
ביצוע סדר הפעולות בצורה נכונה – כך שתמיד יהיו מספיק Pods שרצים.
בחינת (probing) ה Pod replicas החדשים – ו rollback במקרה של בעיה.
למשל: בדוק שה pod replica החדש שעלה הוא תקין (ע״פ תנאים מסוימים, מה שנקרא Readiness check) – לפני שאתה מעלה עוד pod replicas מהגרסה החדשה או מוריד עוד ישנים.
ישנן מגוון הגדרות בכדי לשלוט בהתנהגות המדויקת.
בתרשים למעלה ערבבתי, לצורך הפשטות, בין entities שהם קונפיגורציה (באפור: deployment, replica set) לבין entities של זמן-ריצה (בכתום: Pod replica). אני רוצה כעת לדייק את הדברים בעזרת התרשים הבא:
קונספט ארכיטקטוני מרכזי בקוברנטיס הוא ה Controllers, שהם בעצם מעין Modules או Plug-Ins של סביבת הניהול של קוברנטיס (ה Control Plane). ה Controllers מאזינים ל API Server הפנימי של קוברנטיס אחר שינויים על ה Resource הרלוונטי להם (Deployment, Service, וכו') או שינויים בדרישות – ואז מחילים את שינויים נדרשים.
בעיקרון ה Controllers רצים ב Reconciliation loop (כמו event loop) שנקרא כך בגלל שכל פעם שיש אירוע (שינוי שנדרש) הם מבצעים פעולה על מנת "ליישר קו" (reconcile) וכך, לעתים בצעדים, ה loop דואג שכל הזמן המצב בשטח יגיע במהרה למצב שהוגדר. מדי כמה זמן הם בודקים את סה"כ ההגדרות ומגיבים לפער – אם קיים. כלומר: גם אם event מסוים פוספס / לא טופל – תוך זמן קצר ה controller יגלה את הפער וישלים אותו.
בניגוד להפשטה המוצגת בתרשים למעלה, Controllers לעולם לא יתקשרו ישירות אחד עם השני (אחרת: הם לא יהיו Pluggable). כל קריאה היא ל API Server, למשל "צור משאב מסוג Replication", שבתורו יפעיל אירוע מתאים שייקלט ע"י ה Replication Controller ויוביל לפעולה.
אנחנו נראה בהמשך את ההגדרות של ה Deployment ואת ה template המדובר.
הנה תיאור דינאמי של תהליך ה deployment:
ה Deployment ישמור את ה replica set הקודם (ועליו כל ההגדרות), על מנת לאפשר תהליך של Rollback.
כמובן שההתנהגות המדויקת של שלב ה Mid (ליתר דיוק: סדרת שלבי ה mid) תלויה מאוד באסטרטגיית ה Deployment שנבחרת.
אני מניח שאתם מכירים את 2 האסטרטגיות המרכזיות, המקובלות בכלל בתעשייה: Rolling deployment ו Blue/Green deployment. קוברנטיס לא תומך היום (בעת כתיבת הפוסט) ב Blue/Green deployments כיכולת-ליבה (אם כי יש מדריכים שמראים כיצד ניתן להשיג זאת, על בסיס יכולות קיימות של קוברנטיס – הנה דוגמה לאחד).
בכלל, כל נושא ה deployments הוא GA רק מגרסה 1.9 (תחילת 2018). כיום קוברנטיס תומך רק באסטרטגיות: "Recreate" (אסטרטגיה סופר פשוטה, בה יש downtime בהגדרה) ו "RollingUpdate" (ברירת המחדל).
הנה שני מקורות, המציגים כ"א כמה תסריטי deployment אפשריים, בהתבסס על יכולות הליבה של קוברנטיס:
מצגת של Cloud Native Computing Foundation (בקיצור: CNCF) – הארגון שהוקם על מנת לקחת אחריות על פרויקט קוברנטיס, ולנהל אותו כ Open Source בלתי-תלוי. יש גם סיכום one-pager של האסטרטגיות שהוא מציג.
פוסט של ארגון בשם Container Solutions – שגם הוא מציג בצורה ויזואלית יפה, את משמעות האסטרטגיות השונות (סט דומה, אך לא זהה לקודם).
אתם כבר אמורים להכיר את 3 המפתחות הראשונים, ולכן נתמקד ב spec:
את הגדרת ה pod ניתן למצוא תחת ה template והן זהות ל Pod שהגדרנו בפוסט הקודם (מלבד label אחד שהוספנו). שימו לב שה metadata של ה Pod מופיע תחת template, ולא במפתח ה metadata של ה manifest.
replicas הוא מספר העותקים של ה pod שאנו רוצים להריץ.
ה selector משמש לזיהוי חד משמעי של סוג ה pod שאנו מתארים. חשוב שניתן label "יציב" שבעזרתו קוברנטיס יידע לקשר ולהשוות אם היו שינויים בין pod templates. אם היה שינוי – עליו לבצע deploy.
למשל: אם שינינו גם את label הגרסה וגם את ה image – איך אפשר לקשר בוודאות שמדובר באותו האפליקציה, ולא בחדשה?
מקובל להשתמש ב label בשם app או app.kubernetes.io/name.
ל labels ניתן להוסיף namespace וקוברנטיס מציע כמה שמות "סטנדרטים" ל labels. אני לא יודע כמה השימוש בהם באמת נפוץ.
על אסטרטגיית ה deployment כבר דיברנו. הנה 2 פרמטרים חשובים של אסטרטגית rolling deployment:
maxUnavailable – הכמות המרבית המותרת של pods שאינם זמינים תוך כדי פעולת deploy. הדבר משפיע כמה pods קוברנטיס יכול "להוריד במכה" כאשר הוא מתקין גרסה חדשה. המספר מתייחס למספר ה pods התקינים בגרסה הישנה + החדשה ביחד, וברירת המחדל היא 25%. ניתן גם לקבוע 0.
maxSurge – הוא פחות או יותר הפרמטר ההופכי: כמה pods חדשים ניתן להרים "במכה". ככל שהמספר גדול יותר – כך ה rolling deployment עשוי להיות מהיר יותר. גם כאן ברירת המחדל היא 25%.
בקיצור גמור: אם יש לנו 4 pod replicas, הערכים שקבענו ב manifest יבטיחו שה cluster תמיד יכיל בין 3 ל 5 pod replicas בזמן deployment.
minReadySeconds – שדה רשות (ערך ברירת מחדל = 0) שמציין כמה שניות לחכות לאחר שה pod מוכן ("ready") לפני שמעבירים לו תעבורה. ההמתנה הזו היא פרקטיקה מקובלת, מכיוון שהנזק מ pod בעייתי שמחובר ל production traffic – עשוי להיות משמעותי. אפשר להיתקל גם בערכים של 20 ו 30 שניות. חשוב להזכיר שערך גבוה יאט את תהליך ה rolling deployment מכיוון שאנו ממתינים ל minReadySeconds – לפני שאנו ממשיכים להחליף עוד pods.
כאן שווה להזכיר את ה Readiness & Liveliness Probes של קוברנטיס. קוברנטיס מריץ ב nodes רכיב טכני הרץ כ container ומבצע בדיקות Health-check על ה pods השונים ב node ומדווח את התוצאות הלאה. כל pod צריך לענות ל2 קריאות: well-known/live./ ו well-known/ready./
מצב ה live הוא אות חיים בסיסי. המימוש המומלץ הוא פשוט להחזיר HTTP 200 OK מבלי לבצע פעולות נוספות. אם התשובה המתקבלת היא לא 2xx – קוברנטיס יאתחל את ה pod הזה מיד.
מצב ה ready אמור להיות עשיר יותר, בד"כ בודקים גישה לבסיס הנתונים ("SELECT 1") או גישה למשאבים קריטיים אחרים ל Pod (למשל: גישה לרדיס, או שירותים אחרים הקריטיים לפעילות ה pod). אם האפליקציה עוברת עדכון (למשל: הטמעת קונפיגורציה חדשה / עדכון caches ארוך) – הדרך הנכונה היא להגדיר אותה כ "לא ready" בזמן הזה.
אם התשובה ל ready היא שלילית, קוברנטיס עשויה לנתק אותו מתעבורה נכנסת עד שיסתדר. אם המצב מתמשך (ברירת המחדל = 3 כישלונות רצופים) – ה pod יעבור restart.
שגיאה נפוצה היא להגדיר את live ו ready אותו הדבר – אבל אז מערבבים פעולות live יקרות מדי, ו restarts מיותרים של pods (כי עשינו restart בעקבות live אחד שכשל, נניח – מתקלת רשת נקודתית ואקראית).
את המניפסט, כמובן, מחילים כרגיל:
$ kubectl apply -f my-deployment.yaml
נוכל לעקוב אחר מצב ה deployment בעזרת הפקודה:
$ kubectl get deployment hello-deploy
אם אנו מגלים שהגרסה לא טובה (נניח: עלה באג חדש ומשמעותי לפרודקשיין), אנו יכולים לבצע rollback. הפקודה:
$ kubectl rollout history deployment hello-deploy
תציג לנו רשימה של revisions של ה deployment. נניח שאנו רוצים לחזור לגרסה 1, עלינו לפקוד:
כאשר מדובר ב RollingDeployment, ה rollback כמובן הוא deploy בפני עצמו שייקח זמן, ויעבוד לפי אותם הכללים של deploy חדש. תאורטית אנו יכולים פשוט לשנות את ה deployment.yaml בחזרה למצב הקודם ולבצע deploy חדש – אי כי זה פחות מומלץ, אפילו רק מטעמי תיעוד.
סיכום
סקרנו את משאבי ה ReplicaSet וה Deployment בקוברנטיס – הדרך העיקרית לעדכן את המערכת ב pods חדשים / מעודכנים, בצורה Resilient.
על הדרך, הרחבנו מעט את ההבנה כיצד קוברנטיס עובד.
עדיין, לאחר שביצענו deployment לא נוכל לגשת ל pods שלנו (בקלות הרצויה). לשם כך עלינו להגדיר עוד משאב-ליבה בקוברנטיס בשם Service, המתייחס ל"קבוצה של Pod replicas בעלי אותו הממשק".
סמנטיקת ה Service מתוכננת להיות הנושא לפוסט הבא בסדרה.
הפוסט הזה נכתב לאנשי-תוכנה מנוסים, המעוניינים להבין את Kubernetes – בהשקעת זמן קצרה. הבאזז מסביב ל Docker ו Docker Orchestration הוא כרגע רב מאוד. דברי שבח רבים מסופרים על הטכנולוגיות הללו, מבלתי להתייחס לפרטים ועם מעט מאוד ראיה עניינית וביקורתית. כאנשי-תוכנה ותיקים אתם בוודאי מבינים שהעולם הטכנולוגיה מלא Trade-offs, וכדאי לגשת לטכנולוגיות חדשות עם מעט פחות התלהבות עיוורת – וקצת יותר הבנה.
אני הולך לספק את הידע בפוסט לא בפורמט ה "From A to Z" כפי שדיי מקובל – אבל ע"פ סדר שנראה לי יותר נכון והגיוני. אני רוצה לדלג על דיון ארוך על ההתקנה, ועוד דיון ארוך על הארכיטקטורה – עוד לפני שאנחנו מבינים מהי קוברנטיס. אני הולך לדלג על כמה פרטים – היכן שנראה לי שהדבר יתרום יותר להבנה הכללית.
בכדי לפשט את הדברים, ניתן פשוט לומר שקוברנטיס היא סוג של סביבת ענן:
אנו אומרים לה מה להריץ – והיא מריצה. אנו ״מזינים״ אותה ב Containers (מסוג Docker או rkt) והגדרות – והיא ״דואגת לשאר״.
אנו מקצים לקוברנטיס כמה שרתים (להלן ״worker nodes״ או פשוט "nodes") שהם השרתים שעליהם ירוצו הקונטיינרים שלנו. בנוסף יש להקצות עוד כמה שרתים (בד״כ – קטנים יותר) בכדי להריץ את ה master nodes – ה״מוח״ מאחורי ה cluster.
קוברנטיס תדאג ל containers שלנו:
היא תדאג להרים כמה containers בכדי לאפשר high availability – ולהציב אותם על worker nodes שונים.
אם יש עומס עבודה, היא תדאג להריץ עוד עותקים של ה containers, וכשהעומס יחלוף – לצמצם את המספר. מה שנקרא auto-scaling.
אם container קורס, קוברנטיס תדאג להחליף אותו ב container תקין, מה שנקרא גם auto-healing.
קוברנטיס מספקת כלים נוחים לעדכון ה containers לגרסה חדשה יותר, בצורה שתצמצם למינימום את הפגיעה בעבודה השוטפת – מה שנקרא deployment.
כפי שראינו בפוסט על Docker – פעולת restart של Container תהיה מהירה משמעותית מ VM, שזה גם אומר לרוב deployments מהירים יותר.
לשימוש בקוברנטיס יש יתרון בצמצום משמעותי של ה Lock-In ל Cloud Vendor [א], והיכולת להריץ את אותה תצורת ״הענן״ גם On-Premises.
הסתמכות על קוד פתוח, ולא קוד של ספק ספציפי – הוא גם יתרון, לאורך זמן, וכאשר הספק עשוי להיקלע לקשיים או לשנות מדיניות כלפי הלקוחות.
קוברנטיס גם מספקת לנו יכולות ליבה של ניהול Infrastructure as Code, היכולת להגדיר תצורה רצויה לתשתיות רשת, אבטחה בצורה הצהרתית ופשוטה – מה שמייתר כלי ניהול תצורה (Provisioning) כגון Chef, Puppet או Ansible – ויכול לחסוך עבודה משמעותית.
יעילות
עם כל היעילות המוגברת שהתרגלנו אליה מריצה בענן בעזרת שירותים כמו AWS EC2 או Azure Virtual Machines (להלן ״ענן של מכונות וירטואליות״) – קוברנטיס מאפשרת רמה חדשה וגבוהה יותר של יעילות בניצול משאבי-חומרה.
בתצורה קלאסית של מיקרו-שירותים, הפופולרית כיום – ייתכן ומדובר בניצולת חומרה טובה בכמה מונים. הכל תלוי בתצורה, אבל דיי טיפוסי להריץ את אותו ה workload של מיקרו-שירותים בעזרת קוברנטיס על גבי 20-50% בלבד מהחומרה שהייתה נדרשת על גבי ״ענן ציבורי של מכונות וירטואליות״.
איך זה קורה? למכונה וירטואלית יש overhead גבוה של זיכרון (הרצת מערכת ההפעלה + hypervisor) על כל VM שאנו מריצים. זה לא כ״כ משמעותי כשמריצים שרת גדול (כיום נקרא בבוז: Monolith) – אך זה מאוד משמעותי כאשר מריצים שרתים קטנים (להלן: מיקרו-שירותים).
מעבר לתקורה הישירה שעתה ציינו, יש תקורה עקיפה וגדולה יותר: כאשר אני מריץ על שרת 4 מיקרו-שירותים בעזרת VMs ומקצה לכל אחד מהמיקרו-שירותים 25% מהזיכרון וה CPU ההגבלה היא קשיחה. אם בזמן נתון שלושה מיקרו-שירותים משתמשים ב 10% ממשאבי המכונה כ״א, אבל המיקרו-שירות הרביעי זקוק ל 50% ממשאבי המכונה – הוא לא יכול לקבל אותם. ההקצאה של 25% היא קשיחה ואינה ניתנת להתגמשות, אפילו זמנית [ב].
בסביבת קוברנטיס ההגבלה היא לא קשיחה: ניתן לקבוע גבולות מינימום / מקסימום ולאפשר מצב בו 3 מיקרו-שירותים משתמשים ב 10% CPU ו/או זיכרון כ״א, והרביעי משתמש ב 50%. אפשר שגם 10 דקות אח״כ המיקרו-שירות הרביעי יהיה idle – ומיקרו-שירות אחר ישתמש ב 50% מהמשאבים.
הכרה חברתית
יהיה לא נכון להתעלם מהתשואה החברתית של השימוש בקוברנטיס. מי שמשתמש היום בקוברנטיס, ובמיוחד בפרודקשן – נתפס כמתקדם טכנולוגית, וכחדשן. ההכרה החברתית הזו – איננה מבוטלת.
כמובן שזו הכרה זמנית, שרלוונטית רק שנים בודדות קדימה. ביום לא רחוק, שימוש בקוברנטיס ייחשב מפגר ומיושן, ועל מנת להיתפס כמתקדמים / חדשנים – יהיה עלינו לאמץ טכנולוגיה אחרת.
יש לי תחושה שפעמים רבות, ההכרה החברתית היא שיקול חזק לא פחות משיקולי היעילות – בבחירה בקוברנטיס. טבע האדם.
מחירים
כמובן שיש לכל הטוב הזה גם מחירים:
קוברנטיס היא טכנולוגיה חדשה שיש ללמוד – וכמות / מאמץ הלמידה הנדרש הוא לרוב גבוה ממה שאנשים מצפים לו.
התסריטים הפשוטים על גבי קוברנטיס נראים דיי פשוטים ואוטומטים. כאשר נכנסת לתמונה גם אבטחה, הגדרות רשת, ותעדוף בין מיקרו-שירות אחד על האחר – הדברים הופכים למורכבים יותר! Troubleshooting – עשוי להיות גם דבר לא פשוט, מכיוון ש"מתחת למכסה המנוע" של קוברנטיס – יש מנגנונים רבים.
ברוב המקרים נרצה להריץ את קוברנטיס על שירות ענן, ולכן נידרש עדיין לשמר מידה של מומחיות כפולה בשני השירותים: לשירות הענן ולקוברנטיס יש שירותים חופפים כמו Auto-Scaling, הרשאות ו Service Discovery (בד"כ: DNS).
הטכנולוגיה אמנם לא ממש ״צעירה״, והיא בהחלט מוכחת ב Production – אך עדיין בסיסי הידע והקהילה התומכת עדיין לא גדולה כמו פתרונות ענן מסחריים אחרים. יש הרבה מאוד אינטגרציות, אך מעט פחות תיעוד איכותי וקל להבנה.
כמו פעמים רבות בשימוש ב Open Source – אין תמיכה מוסדרת. יש קהילה משמעותית ופעילה – אבל עדיין הדרך לפתרון בעיות עשויה להיות קשה יותר מהתבססות על פתרון מסחרי.
גם בשימוש ב״קוברנטיס מנוהל״ (EKS, AKS, ו GKE), החלק המנוהל הוא החלק הקטן, והשאר – באחריותנו.
האם החיסכון הצפוי מניהול משאבים יעיל יותר, יצדיק במקרה שלכם שימוש בסביבה שדורשת מכם יותר תפעול והבנה?
במקרה של ניהול מאות או אלפי שרתים – קרוב לוודאי שזה ישתלם.
שימוש בקוברנטיס עשוי לפשט את סביבת התפעול, וה Deployment Pipeline. ההשקעה הנדרשת היא מיידית – בעוד התשואה עשויה להגיע רק לאחר זמן ניכר, כאשר היישום הספציפי באמת הגיע לבגרות.
במקרים לא מעטים, ארגונים נקלעים לשרשרת של החלטות שנגזרות מצו האופנה ובניגוד לאינטרס הישיר שלהם: עוברים למיקרו-שירותים כי ״כך כולם עושים״ / ״סיפורי הצלחה״ שנשמעים, משם נגררים לקוברנטיס – כי יש להם הרבה מאוד שרתים לנהל, שכבר נהיה דיי יקר. לו היינו עושים שיקולי עלות/תועלת מול המצב הסופי – כנראה שהרבה פעמים היה נכון לחלק את המערכת למודולים פשוטים, או להשתמש במיקרו-שירותים גדולים ("midi-services") – וכך לשלוט טוב יותר בעלויות והמורכבויות האחרות.
קוברנטיס בפועל
דיברנו עד עכשיו על עקרונות ברמה הפשטה גבוה. בואו ניגש לרמה טכנית קצת יותר מוחשית.
לצורך הדיון, נניח שהעברנו כבר את כל השירותים שלנו לעבוד על-גבי Docker וגם התקנו כבר Cluster של קוברנטיס. זה תהליך לא פשוט, שכולל מעבר על כמה משוכות טכניות לא קלות – אך נניח שהוא נגמר. בכדי להבין קוברנטיס חשוב יותר להבין מה יקרה אחרי ההתקנה, מאשר להבין את ההתקנה עצמה.
לצורך הדיון, נניח שאנו עובדים על AWS ו EKS ואמזון מנהלים עבורנו את ה Masters nodes. ה Worker nodes שלנו נמצאים ב Auto-Scaling Group – מה שאומר שאמזון תנהל עבורנו את ה nodes מבחינת עומס (תוסיף ותוריד מכונות ע״פ הצורך) והחלפת שרתים שכשלו. זה חשוב!
אנחנו גם משתמשים ב ECR (קרי Container Registry מנוהל) , ואנו משתמשים בכל האינטגרציות האפשריות של קוברנטיס לענן של אמזון (VPC, IAM, ELB, וכו׳). התצורה מקונפגת ועובדת היטב – ונותר רק להשתמש בה.
אנחנו רק רוצים ״לזרוק״ קונטיינרים של השירותים שלנו – ולתת ל״קסם״ לפעול מעצמו. רק לומר בפשטות מה אנחנו רוצים – ולתת לקוברנטיס לדאוג לכל השאר!
יצירת Pod
הפעולה הבסיסית ביותר היא הרצה של Container. בקוברנטיס היחידה האטומית הקטנה ביותר שניתן להריץ נקראת Pod והיא מכילה Container אחד או יותר. כרגע – נתמקד ב Pod עם Container יחיד, זה יהיה המצב ברבים מהמקרים.
אני מניח שאנחנו מבינים מהו Container (אם לא – שווה לחזור צעד אחורה, ולהבין. למשל: הפוסט שלי בנושא), ויש לנו כבר Image שאנו רוצים להריץ ב ECR.
בכדי להריץ Container, עלינו לעדכן את קוברנטיס ב manifest file המתאר Pod חדש מצביע ל container image. קוברנטיס ירשום את ה Pod ויתזמן אותו לרוץ על אחד מה nodes שזמינים לו.
כאשר ה node מקבל הוראה להריץ Pod עליו להוריד את ה container image – אם אין לו אותו כבר. כל node מחזיק עותקים עצמאיים של ה container images משיקולים של high availability.
קובץ ה manifest בקוברנטיס מורכב מ 4 חלקים סטנדרטיים:
גרסת ה API
הפורמט הוא לרוב / אבל כמה הפקודות הבסיסיות ביותר בקוברנטיס נמצאות תחת API Group שנקרא core – ולא צריך לציין אותו.
ה API של קוברנטיס נמצא (בעת כתיבת הפוסט) בגרסה 1.13 – אז למה גרסה 1? ניהול הגרסאות בקוברנטיס הוא ברזולוציה של משאב. הקריאה לייצור pod היא עדיין בגרסה 1 (כמו כמעט כל ה APIs. בעת כתיבת הפוסט אין עדיין גרסת v2 לשום API, מלבד v2alpha או v2beta – כלומר גרסאות v2 שעדיין אינן GA).
סוג (kind) – הצהרה על סוג האובייקט המדובר. במקרה שלנו: Pod.
metadata – הכולל שם ו labels שיעזרו לנו לזהות את ה pod שיצרנו.
ה labels הם פשוט זוגות key/value שאנחנו בוחרים. הם חשובים מאוד לצורך ניהול Cattle של אובייקטים, והם בלב העבודה בקוברנטיס.
spec – החלק המכיל הגדרות ספציפיות של המשאב שהוגדר כ "Type".
name – השם שניתן ל container בתוך ה Pod, וצריך להיות ייחודי. במקרה של container יחיד בתוך ה pod – אין בעיה כזו.
image – כמו בפקודת docker run…
ports – ה port שיהיה published. TCP הוא ערך ברירת-המחדל, אך הוספתי אותו בכדי לעשות את ה Yaml לקריא יותר.
תזכורת קצרה על Yaml:
פה ייתכן וצריך לעצור שנייה ולחדד כמה מחוקי-הפורמט של Yaml. ייתכן ונדמה לכם ש Yaml הוא פורמט פשוט יותר מ JSON – אבל זה ממש לא נכון. זה פורמט "נקי לעין" – אבל מעט מורכב.
רשימה ב Yaml נראית כך:
mylist:
- 100
- 200
"mylist" הוא ה key, והערך שלו הוא רשימה של הערכים 100 ו 200. כל האיברים שלפניהם הסימן " – " ובעלי עימוד זהה – הם חברים ברשימה. סימן ה Tab ברוב ה Editors מתתרגם ל 2 או 4 רווחים. ב Yaml הוא שקול לרווח אחד, ולכן שימוש בו הוא מקור לבעיות ובלבולים. הימנעו משימוש ב Tab בתוך קבצי Yaml!
המבנה הבא, שגם מופיע ב manifest (ועשוי לבלבל) הוא בעצם רשימה של Maps:
"channel" הוא המפתח הראשי, הכולל רשימה. כאשר יש "מפתח: ערך" מתחת ל"מפתח: ערך" באותו העימוד – משמע שמדובר ב Map. כלומר, המפתח "channel" מחזיק ברשימה של שני איברים, כל אחד מהם הוא מפה הכוללת שני מפתחות "name" ו "password".
אם נחזור לדוגמה של הגדרת ה container ב manifest למעלה, בעצם מדובר במפתח "containers" המכיל רשימה של איבר אחד. בתוך הרשימה יש מפה עם 3 מפתחות ("image", "name", ו "ports") כאשר המפתח האחרון "ports" מכיל רשימה עם ערך יחיד, ובה מפה בעלת 2 entries.
עכשיו כשיש לנו manifest, אנחנו יכולים להריץ את ה Pod:
$ kubectl apply -f my-manifest-file.yml
kubectl הוא כלי ה command line של קוברנטיס. פקודות מסוימות בו יזכירו לכם את ה command line של docker. במקרה הזה אנו במקרה הזה אנו מורים לקוברנטיס להחיל קונפיגורציה. הפרמטר f- מציין שאנו מספקים שם של קובץ.
תוך כמה עשרות שניות, לכל היות, ה pod שהגדרנו אמור כבר לרוץ על אחד ה nodes של ה cluster של קוברנטיס.
אנו יכולים לבדוק אלו Pods רצים בעזרת הפקודה הבאה:
$ kubectl get pods
עמודה חשובה שמוצגת כתוצאה, היא עמודת הסטטוס – המציגה את הסטטוס הנוכחי של ה pod. אמנם יש רשימה סגורה של מצבים בו עשוי להיות pod, אולי עדיין הסטטוס המדווח יכול להיות שונה. למשל: הסטטוס ContainerCreating יופיע בזמן שה docker image יורד ל node. זה מצב נפוץ – אך לא מתועד היטב. את הסטטוס ניתן למצוא בעיקר… בקוד המקור של קוברנטיס.
הפקודה הבאה (וריאציות), בדומה לפקודת ה Docker המקבילה – תציג את הלוגים של ה Container ב Pod :
$ kubectl logs my-pod
אם ב Pod יש יותר מ-2 containers (מצב שלא אכסה בפוסט), הפקודה תציג לוגים של ה container הראשון שהוגדר ב manifest. אפשר לציין את שם ה container כפי שצוין ב manifest – וכך להגיע ל container נתון בתוך Pod-מרובה containers.
עבור תקלות יותר בסיסיות (למשל: ה pod תקוע על מצב ContainerCreating וכנראה שה node לא מצליח להוריד את container image) – כדאי להשתמש בפקודה:
$ kubectl describe pods my-pod
התוצאה תהיה ססטוס מפורט שיכיל את הפרטים העיקריים מתוך ה manifest, רשימה של conditions של ה pod, ורשימת כל אירועי-המערכת שעברו על ה pod מרגע שהורנו על יצירתו. הנה דוגמה להפעלה הפקודה (מקור):
Name: nginx-deployment-1006230814-6winp Node: kubernetes-node-wul5/10.240.0.9 Start Time: Thu, 24 Mar 2016 01:39:49+0000 ... Status: Running IP: 10.244.0.6 Controllers: ReplicaSet/nginx-deployment-1006230814 Containers: nginx: Container ID: docker://90315cc9f513c750f244a355eb1149 Image: nginx Image ID: docker://6f623fa05180298c351cce53963707 Port:80/TCP Limits: cpu: 500m memory: 128Mi State: Running Started: Thu, 24 Mar 2016 01:39:51+0000 Ready:True Restart Count:0 Environment:<none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-5kdvl (ro) Conditions: Type Status Initialized True Ready True PodScheduled True Volumes: default-token-4bcbi: Type: Secret (a volume populated by a Secret) SecretName: default-token-4bcbi Optional:false ... Events: FirstSeen LastSeen Count From SubobjectPath Type Reason Message ------------------------------------------------------------ 54s 54s 1{default-scheduler } Normal Scheduled Successfully assigned nginx-deployment-1006230814-6winp to kubernetes-node-wul5 54s 54s 1{kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Pulling pulling image "nginx" 53s 53s 1{kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Pulled Successfully pulled image "nginx" 53s 53s 1{kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Created Created container with docker id 90315cc9f513 53s 53s 1{kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Started Started container with docker id 90315cc9f513
ניתן גם, בדומה ל Docker, לגשת ישירות ל console של ה container שרץ ב pod שלנו בעזרת הפקודה:
במקרה הזה ציינתי את שם ה container, אם כי לא הייתי חייב.
נראה לי שזה מספיק, לבינתיים. בואו נסגור את העניינים:
$ kubectl delete -f my-manifest-file.yml
הפעולה הזו עלולה להיראות מוזרה ברגע ראשון. הסרנו את הקונפיגורציה – ולכן גם ה Pod ייסגר?
לשימוש בקוברנטיס יש שתי גישות עיקריות:
גישה אימפרטיבית – בה מורים לקוברנטיס איזה שינוי לבצע: להוסיף משאב, לשנות משאב, או להוריד משאב.
פקודות כגון kube ctl create או kubectl replace הן בבסיס הגישה האימפרטיבית.
גישה דקלרטיבית – בה מורים לקוברנטיס מה המצב הרצוי – והוא יגיע עליו בעצמו.
פקודת kubectl apply – היא בבסיס הגישה הדקלרטיבית. אפשר להגדיר כמעט הכל, רק באמצעותה.
החלת patch על גבי קונפיגורציה קיימת הוא משהו באמצע: זו פקודה דקלרטיבית, אך מעט חורגת מה lifecycle המסודר של הגישה הדקלרטיבית הקלאסית. סוג של תרגיל נינג'ה.
כמובן שהגישה הדקלרטיבית נחשבת קלה יותר לשימוש ולתחזוקה לאורך זמן – והיא הגישה הנפוצה והשלטת.
מכיוון שאין לנו הגדרה אלו Pods קיימים סה"כ במערכת – לא יכולנו לעדכן את המערכת בהגדרה הכוללת – ולכן הסרנו את המניפסט.
סיכום
ניסינו להגדיר בקצרה, ובצורה עניינית מהם היתרונות הצפויים לנו משימוש בקוברנטיס – מול הצפה של החסרונות והעלויות.
לא פעם קראתי מאמרים שמתארים את קוברנטיס כמעבר מהובלת מסע על גבי פרד – לנסיעה ברכב שטח יעיל! אני חושב שההנחה הסמויה ברוב התיאורים הללו היא שהקוראים עדיין עובדים על גבי מערכות On-Premises ללא טכנולוגיות ענן. מעבר משם לקוברנטיס – היא באמת התקדמות אדירה.
המעבר משימוש ב"ענן של מכונות וירטואליות" לקוברנטיס – הוא פחות דרמטי. קוברנטיס תספק בעיקר יעילות גבוהה יותר בהרצת מיקרו-שירותים, וסביבה אחידה וקוהרנטית יותר למגוון פעולות ה deployment pipeline. עדיין, נראה שקוברנטיס היא סביבה מתקדמת יותר – ואין סיבה שלא תהפוך לאופציה הנפוצה והמקובלת, בתוך מספר שנים.
אחרי ההקדמה, עברנו לתהליך יצירה של Pod בסיסי, ובדרך עצרנו בכמה נקודות בכדי להדגים כיצד התהליך "מרגיש" בפועל.
חשוב לציין שה Pod שהגדרנו הוא עצמאי ו"חסר גיבוי" – מה שנקרא "naked pod". אם naked pod כשל מסיבה כלשהי (הקוד שהוא מריץ קרס, או ה node שעליו הוא רץ קרס/נסגר) – הוא לא יתוזמן לרוץ מחדש. מנגנון ה auto-healing של קוברנטיס שייך לאובייקט / אבסטרקציה גבוהה יותר בשם ReplicaSet. אבסטרקציה מעט יותר גבוהה, שבה בדרך כלל משתמשים – נקראת Deployment.
כיסינו דיי הרבה לפוסט אחד. הנושאים הללו מצדיקים פוסט משלהם.
[א] אל דאגה! לספקי הענן יש אינטרס עליון לגרום לנו ל Lock-In גם על סביבת קוברנטיס. לאחר שהניסיונות להציע חלופות ״מקומיות״ לקוברנטיס כשלו – רק טבעי שהם יתמקדו בלהציע יכולות שיפשטו את השימוש בקוברנטיס, אך גם יוסיפו סוגים חדשים של Lock-In. בכל מקרה, ברוב הפעמים אנו כבר תלויים בתשתיות כמו RDS, Athena, S3 ועוד – ולכן כבר יש Lock-In מסוים גם בלי קשר לקוברנטיס.
"Cloud Agnostic Architecture״ הוא בסה״כ מיתוס, השאלה היא רק מידת התלות.
[ב] שווה לציין שזה המצב בענן ציבורי. כששכן שלנו למכונה ב AWS רוצה יותר CPU – למה שנסכים לתת לו? אנחנו משלמים על ה ״slice״ שלנו במכונה – שהוגדר בתנאי השירות.
בפתרונות של ענן פרטי (כמו VMWare) ישנן יכולות ״ללמוד״ על brusts של שימוש בקרב VM ולהתאים את המשאבים בצורה יעילה יותר. כלומר: המערכת רואה ש VM מספר 4 דורש יותר CPU אז היא משנה, בצורה מנוהלת, את ההגדרות הקשיחות כך שלזמן מסוים – הוא יקבל יותר CPU מה VMs האחרים הרצים על אותה המכונה. טכנולוגית ה VM עדיין מקצה משאבים בצורה קשיחה – אך תכנון דינמי יכול להגביר יעילות השימוש בהם. זה יכול לעבוד רק כאשר כל ה VMs על המכונה שייכים לאותו הארגון / יש ביניהם הסכמה.
T3/T2 instances ב EC2 הם VMs שעובדים על עיקרון דומה: ב״חוזה״ שלנו רשום שה instance יכול לעבוד ב burst ולקבל יותר משאבים – אך עדיין יש פה עבודה לפי חוזה, ולא אופטימיזציה גלובלית של המשאבים על המכונה (מכיוון שה VMs שייכים לארגונים שונים).
בכל זאת, Docker הוא כנראה אחד הנושאים הנכתבים ביותר בשנתיים האחרונות [א]. יש הרבה יותר חומר על Docker מאשר על טכנולוגיות אחרות וותיקות ושנעשה בהן שימוש רחב יותר. אפילו יש כמה פוסטים בעברית על Docker.
מה אני הולך לעשות אחרת?
אני לא הולך להתחיל מ"היסודות" (גישה סיסטמטית, אך לא תמיד הכי מעניינת) – אלא מצורך ממשי, ולהתקדם לפיו.
אני לא הולך לעשות מדריך סופר-נקי. יהיו לנו תקלות, דברים לא יעבדו. נחשוב למה (נוסיף מידע) – ונפתור אותם. תקלות וכישלונות הוא דבר שקל יותר לזכור (יש פה סיפור…), והוא מאוד טיפוסי במהלך העבודה עם infrastructure.
הפוסט מניח שאתם יודעים קצת על לינוקס ובכלל, ועל Docker מספיק להכיר ש:
Container הוא ״כמו lightweight VM״ (הגדרה דיי נכונה, אך ממש לא מדויקת). הקונטיינר צורך הרבה פחות משאבים ומציב תקורת פעולה נמוכה מ VM – אבל גם מספק רמת הפרדה נמוכה יותר = פחות אבטחה, פחות הגנה על המערכת מהתרסקויות.
כל עוד המחשב מריץ רק תהליכים שאתם סומכים עליהם + אתם ערוכים לספוק קריסה של מכונה בודדת (לא יקרה המון, יקרה מעט יותר) – אז הרצת קונטיינרים היא דבר הגיוני.
מכיוון שה Container הוא לא ״מכונה״ אלא תהליך שרץ תחת הגבלות / בצורה חצי-מבודדת, הוא עדיין עשוי להיות מושפע מתהליכים אחרים / Containers אחרים הרצים על אותה המכונה ו/או הגדרות משותפות של מערכת ההפעלה.
אתם יודעים את ההבדל בין Container (מופע ההרצה) ל Image (התוכן שעל בסיסו רץ ה container).
אולי שמעתם משהו על Layers… ועל Dockerfile…. זה מספיק.
אז יאללה, הנה ה Use-case הבסיסי ומעשי שלנו:
אני רוצה לנסות איזו ספריה / כלי בגרסה חדשה יותר ממה שיש לי, מבלי להתקין על המחשב המקומי (גם לחסוך התקנה מורכבת יותר, וגם להימנע מ״לכלוך״ שיישאר אח״כ.).
אם זו ספריה נפוצה, בטח נמצא לה docker image מוכן. במקרה שלי, אני רוצה להתקין את MySQL 8 על המחשב ולנסות אותו.
אני מבטיח שלא הכל ילך חלק… ויהיו לנו כמה תקלות להתמודד איתן – וללמוד מהן, ממש כמו שקורה במציאות.
הנה מתחילים
אני מניח שאתם רצים על מק או Windows – ויש לכם את חבילת ה Docker Desktop (לשעבר/שיפור של Docker Toolbox) מותקנת.
Docker מתבסס על יכולות קרנל של לינוקס, ופעם להתקין אותו על מק היה קצת מסובך. היום חבילת ה Docker Desktop מתקינה בקלות את כל, (או כמעט כל) הכלים של Docker:
התמנון הוא compose, רובוט עם אקווריום הוא docker-machine, הדגים שנושאים קונטיינר הם docker swarm (אבל מאז הלוגו הפך לחבורת לווייתנים הנושאים את הקונטיינר). לא הצלחתי לזהות את הבחור האחרון בתיבה.
וודאו שכאשר אתם מקלידים ב console את הפקודה docker –version אכן מוצגת מספר גרסה (18 בעת כתיבת הפוסט).
בכדי להתחיל את התסריט שדיברנו עליו, אלך ל DockerHub ואחפש אחר ״MySQL״.
DockerHub הוא רפוזיטורי הציבורי הגדול לשיתוף של Docker Images.
הנה תוצאות החיפוש:
ישנם שלושה סימונים ששווים התייחסות קצרה:
Official Image – מכיוון שההצלחה של Docker מבוססת על מגוון של Images איכותיים שזמינים, החברה שמאחורי Docker בחרה לתת חסות לחלק מה images הפופולארים ב dockerHub, ואלו מסומנים כ "Official images".
המשמעות היא שצוות של החברה עושה Review ל Dockerfiles ותוכן ה images, מוודא שיהיו עדכונים תכופים ל image, ומבצע סריקות אבטחה ל images הללו (ניתן לראות את התוצאות ב tab ה TAGS של ה image הספציפי.
אחת מסכנות האבטחה הקשורות ל Docker הוא מנגנון השכבות, שעושה caching לשכבות ועלול לעצור אותנו מלקבל עדכוני-אבטחה חשובים לאורך זמן. הפתרון לסיכון הזה הוא לרענן את ה images שלנו, גם בשכבות הנמוכות – מדי פעם.
אם אתם מתכננים להשתמש ב Image בפרודקשיין ויש Official image שמתאים לכם – מומלץ מאוד לבחור בו, או ב image המבוסס עליו, שלא נראה שמוסיף סיכוני אבטחה.
Verified Publisher – למרות תווית הזהב, שעשויה להראות יוקרתית יותר, מדובר בסה"כ ב image שהועלה מחשבון שאומת כשייך לחברה שטוענת שהוא ברשותה. בדף ה image יהיה קישור לפרופיל החברה שיעזרו למשתמש לוודא במי מדובר. זה חשוב בכדי לא להוריד malicious images, אבל זה לא אומר שום-דבר על איכות התוכן עצמו. להזכיר: גם חברות מוכרות עלולות להוציא תוצרים מביכים.
תווית ה "Docker Certified" (שאיננה נגזרת מתווית ה Verified Publisher) אומרת ש:
ה Image המדובר מבוסס על Official Image.
ה Image עבר כלי של Docker לבדיקת כמה היבטים של אבטחה ופעולה בסיסית.
למרות שזה לא טוב כמו Official Image שעובר review ידני, זה עדיין סימן טוב שכדאי להתייחס אליו בחיוב – במיוחד עם השינויים מה Official image מובנים לכם.
ניכנס להפצה הרשמית של MySQL:
כיאה ל Official Image, יש די מידע בדף ה image:
הנה שורת הפקודה על מנת להוריד את ה image מקומית למחשב. פשוט!
הנה גרסאות עיקריות של ה Image, וה Dockerfiles שאיתן נבנו. ה Dockerfile הוא מעניין מאוד ומלמד אותנו מה יש ב Image.
בהמשך נכתוב גם Dockerfiles בעצמנו – ולכן השפה הזו תהיה ברורה וטבעית לנו.
אני יכול לקרוא ביקורות על ה Image – לוודא שהוא לא #פח. לשמחתי: הביקורות מצוינות!
אני יכול לראות את ה Tags השונים. Tags, בניגוד למה שניתן לחשוב ע״פ השם, הן לא מילות מפתח – אלא גרסאות שונות של ה image. היה נכון יותר לקרוא ל Tags בשם "Versions".
ה Dockerfile
לפני שאני מתקין מקומית את ה MySQL 8 image, בעזרת הפקודה docker pull mysql – אני רוצה להתעכב מעט ולצלול לשנייה ל Dockerfile של MySQL 8 (הנה התיעוד הרשמי והמוצלח של ה Dockerfile), וננסה לקלוט כמה תובנות חשובות.
הקובץ שנסתכל עליו הוא אמיתי – שזה חשוב. לא חשוב להבין את כל הפרטים, רק להתמקד במבנה הקובץ, ובכמה פקודות עיקריות שנשים עליהן דגש.
הנה תחילת הקובץ:
פקודת ה FROM מתחילה build חדש ומציינת על איזה image בסיס אנחנו מתבססים: זה יכול להיות image של "מערכת הפעלה" או image שבניתם ואתם רוצים להרחיב.
אם יש בקובץ כמה פקודות FROM – כל אחת תייצר image אחר. השימוש העיקרי לכך הוא multi-state build (נושא מתקדם).
כדי שה image יהיה קטן ככל האפשר (פחות זמן/נפח תעבורה בהורדה, לפעמים גם פחות צריכת זיכרון בהרצה) – משתמשים לרוב בגרסאות מצומצמות של הפצות לינוקס.
חשוב להתרגל: בהפצה מינימלית לא מותקן כמעט שום דבר. כאשר נרצה לעבוד ב shell של container שמריץ את ה image – לרוב נצטרך להתקין את ה "utilities" שאנו רגילים להתייחס לקיומם כמובן מאליו.
השימוש ב capital letters לכתיבת פקודות ה Dockerfile (כמו FROM) איננה חובה, אבל היא קונבנציה שימושית – כמו בשפת SQL.
הפצה נפוצה במיוחד של לינוקס לשימוש ב Docker היא Alpine, אשר קטנה מ 5MB (קטנה פי 20 מהפצת אובונטו סטנדרטית), נחשבת מאובטחת היטב ואמינה. הנה סיקור קצר ומעניין שלה.
פקודת RUN היא פקודת-מפתח, המבצעת שינוי ב Image הבסיס, ויוצרת עליו Layer חדש.
כל פקודת RUN מייצרת Layer, ולכן, על מנת לחסוך ב Layers -נוהגים לשרשר פקודות כאשר יש להן משמעות דומה. זו הסיבה שיש כ"כ הרבה שרשורים (&&) על גבי פקודה בודדת.
לסדר פקודות ה RUN בקובץ יש משמעות בסדר בניית ה layers. עוד פרטים – בהמשך.
והנה סוף הקובץ:
דרך נוספת להוסיף layer ל image הוא פקודת ADD, או הגרסה הפשוטה והשימושית יותר שלה: פקודת COPY – המוסיפה קבצים ל image מתוך פעולות העתקה.
לכל קובץ Dockerfile יש פקודת CMD יחידה, שהיא הפקודה-ברירת המחדל שתרוץ בעת הרצת ה container.
אם הפקודה הזו מורכבת – משתמשים ב shellscript שהועתק לתוך ה image.
[נושא מתקדם] כאשר מריצים את ה container – יש אפשרות לשלוח כפרמטר פעולה אחרת שתרוץ, במקום הפעולה שצוינה CMD.
אם זה לא מצב טיפוסי ל image (ניתן להפעיל פעולות גם על container לאחר שרץ) – אזי משתמשים בפקודת ENTRYPOINT לציין פקודת בסיס, כאשר ה command (אם הוגדר ע"י CMD או קלט חיצוני) – ישורשר אליה כפרמטר/פרמטרים.
רק פקודת ה ENTRYPOINT האחרונה בקובץ – תופסת.
לפקודות CMD ו ENTRYPOINT יש שתי צורות כתיבה עיקריות:
shell form – שורת טקסט רגילה – תפעיל את ה shell בכדי לפענח אותו
מאבדים את היכולת של הקונטיינר לקבל סיגנלים מהמערכת שמארחת אותו
נחשב פורמט פחות אמין מבחינת אבטחה, כי אפשר לעשות כל מיני תרגילי shell תוקפניים
פחות אמין מבחינת ביצוע, כי סיכוי טוב שכל מיני פקודות שאנו מנסים להשתמש בהן (למשל tr או xargs) – פשוט לא זמינות בהפצה המינימלית של הלינוקס שאנו משתמשים בה.
execution form – קלט כמערך JSON: פקודה ואז פרמטרים – כמו שתי הדוגמאות בקובץ הנ"ל, כאשר המערך כולל רק איבר יחיד, ולכן אינו כולל פרמטרים.
זהו הפורמט המומלץ והנפוץ לשימוש.
אפשר בפרמטרים להתייחס למשתני סביבה של לינוקס. אין בעיה.
חסרון נפוץ: לא ניתן לשרשר פקודות בעזרת && (פונקציה של ה shell).
פקודת EXPOSE מציינת לאילו ports ה container יאזין. זה עדיין לא מספיק על מנת לקבל תקשורת, כי בנוסף יש להפעיל (לרוב: בעת הרצת הקונטיינר) פקודה בשם publish (בעזרת הארגומנט p-) שתחליט מהיכן אנו יכולים לקבל את התקשורת.
בגדול אפשר לתאר 3 מצבים:
ללא expose – הקונטיינר לא יוכל לקבל תקשורת. עדיין יש לכך שימושים.
עם expose, אך ללא publish – הקונטיינר יוכל לקבל תקשורת רק מ containers אחרים.
עם expose ועם publish – הקונטיינר יוכל לקבל תקשורת מטווח כתובות ה ip שהוגדר.
הפורטים אליהם מתייחסים הם מסוג tcp (ברירת המחדל) או udp, כאשר tcp הוא הבסיס גם ל HTTP, כלומר: על מנת לאפשר תקשורת HTTP די לחשוף port מסוג tcp.
Docker Image Layers
אוקי. בהנחה שהצלחנו לקלוט משהו מה Dockerfile, בואו נמשיך בתסריט המרכזי שלנו. נוריד את ה image של MySQL, בעזרת פקודת docker pull (סט הפקודות מול ה docker registry דיי מזכיר את git):
אנחנו יכולים ממש לראות כיצד יורדים בנפרד/במקביל ה Layers השונים.
אם ל Docker יש כבר layers מסוימים ב "repository המקומי" – הוא לא יוריד אותם, וכך יחסוך זמן.
כדי להדגים את זה, הנה אני אוריד image נוסף של mysql, הפעם עם tag של "5.7.24" (כאשר לא מציינים תג, ברירת המחדל היא latest:):
כפי שאתם יכולים לראות – חסכנו הורדה של רוב ה layers (הכוללים הרבה MBs).
Docker מסוגל לעשות שימוש חוזר ב layers רק "מלמטה – למעלה". ה Layer הראשון שאנו נתקלים בו שאיננו כבר ב repository יגרום להורדה מחדש של כל ה layers מעליו. מסיבה זו לפעמים שווה לנסות ולסדר את פקודות ה RUN/COPY/ADD ב Dockerfile כך שהשוני בין images שונים יהיה מאוחר ככל האפשר (ולכן – קטן ככל האפשר, ורק ה layers החסרים יעודכנו).
מימוש ה Layers ב Docker נועד לא רק עבור הורדת images – אלא גם עבור זמן-הריצה.
בעזרת מנגנון הנקרא union mount (והמימוש שלו: aufs או overlayFS) יכול Docker לבנות את "מערכת הקבצים" הזמינה לכל container בעזרת הרכבת סדרה של mounts בזה על גבי זה.
לדוגמה (בהתבסס על התרשים הנ"ל): עבור "container 1", אנו עושים mount של ה image של Debian ואז mount ל layer שמוסיף את הקבצים של vim, ואז mount של layer המוסיף את הקבצים של nginx ואז layer אחרון (שהוא היחידי שאינו read-only) עבור כתיבות לדיסק שנעשות ע"י container 1 עצמו.
באופן זה אין צורך "להעתיק", אפילו מקומית, את הקבצים אותם דורש ה container. כל ה containers בתמונה הנ"ל באמת עושים שיתוף של עותק יחיד של Debian layer ושל ה vim layer – המגיעים ישירות מה "repository המקומי".
אם אחד מה containers מוחק את ה binaries של vim – זה קורה רק ב layer שלו (בה מותרת כתיבה), מבלי להשפיע על אף אחד מה containers האחרים. הארכיטקטורה הזו, שאינה דורשת העתקות – תומכת היטב באתחול מהיר במיוחד של containers, ובצמצום משאבים (למשל caches ברמת ה kernel). זה אחד ה"שוסים" של Docker.
אם כבר הזכרנו את העובדה, שווה לציין שגם בבניית docker image, מחיקה של קבצים בעצם רק מוסיפה layer נוסף בו הקבצים לא נמצאים – ולכן לא מקטינה את גודל ה image הכולל. אם רוצים לחסוך בגודל, יש לבנות את ה Layer המדובר בלי אותם קבצים מלכתחילה.
נמשיך בתסריט שלנו. הפעולה האחרונה שלנו הייתה להוריד שני images (אסופות של layers) ל repository המקומי.
בואו נקרא לפקודת docker image list – בכדי לראות את המציאות הזו בשטח. הנה רשימת כל ה images ב "repository המקומי" (לא מונח רשמי, אך מונח שקל להבין):
גודל ה image הוא פרטמר שיש לשים לב אליו, במיוחד כאשר אנחנו בונים images בעצמנו. נרצה לצמצם את הגודל ככל האפשר.
ה image id הוא בעצם תחילית של ה hash (הייחודי) של ה image.
אפשר לזהות image ע"י name:tag – אבל לא תמיד הזיהוי יהיה "יציב" (למשל: mysql:latest נדרס ע"י עותק חדש יותר של latest)
דרך זיהוי יותר יציבה היא בעזרת ה image ID החלקי (תחילית של 12 סימנים ראשונים ב hash) או ה image ID המלא (GUID באורך 256 ביט).
כבר הזכרנו שה Tag הוא בעצם מספר גרסה. שימו לב ש `latest` הוא ערך ברירת המחדל של tags ב Docker – ואין שום מחויבות שזו באמת הגרסה האחרונה שזמינה.
עבור image מתוחזק-היטב כמו MySQL – זו כנראה באמת הגרסה האחרונה (בעת ההורדה) – אם כי אין מנגנונים של Docker שעוזרים לתחזק זאת (זו עבודה "ידנית" של מי שמנהל את ה images).
מסיבה זו – ההמלצה המקובלת היא להימנע משימוש ב tag בשם latest ו/או להימנע מאי-ציון tag ל images שאנחנו בונים – אלא אם אתם מנהלים בדייקנות ש latest תמיד תהיה הגרסה האחרונה. ייתכן ובעתיד ה ecosystem של docker יספק פתרון אמין לניהול גרסאות – אבל בינתיים זה בידכם.
אני רוצה לצלול לרגע, ולהראות את הקשר (הישיר) בין ה Dockerfile של Mysql8 שראינו למעלה, וה image שירד אלינו למחשב. נעשה זאת בעזרת הפקודה docker history המציגה את ההיסטוריה של image נתון:
מכיוון שלא ציינתי tag, אני מקבל את ה latest – במקרה שלנו: MySQL 8.
אם נשווה את ה layers קל מאוד למצוא את ההתאמה ל Dockerfile של MySQL8 שראינו למעלה. הקדישו דקה ונסו! כפי שאמרנו, כל פעולת RUN / ADD / COPY מתרגמת ל Layer פיסי חדש. כל פעולה אחרת יוצרת מה שנקרא temporary intermediate image (שלב טכני בזמן היצירה) – וההשפעה "תמוזג" לתוך ה Layer הפיסי הבא.
אני יכול לזהות intermediate layers ע"פ כך שיש להם גודל של 0B.
Docker מפעיל shell בבניית ה image על כל פעולת RUN, וכל פעולה אחרת (כולל COPY/ADD – המבוצעות ע"י Docker עצמו) – מסומנות כ (nop)# – קיצור של no operation.
אם בעבר בעמודת ה IMAGE היה מופיע ה id של ה layer (מלבד intermediate layers שאין להן id), מסיבות הקשורות לאבטחה החליטו להוריד את העמודה הזו – ולכתוב שם – תכתובת מיותרת ומבלבלת. היה עדיף להסיר את העמודה וזהו.
בואו נריץ את ה Container
עכשיו שיש לנו את ה Image, אנו יכולים להריץ אותו – בדמות container (שהוא ה"מופע"). הרצה של container היא דיי פשוטה:
אופס! מה קרה כאן?
השגיאה הזו היא לא שגיאה של Docker, אלא של ה image שאנחנו מריצים. הוא מצפה ל Environment Variable מסוים. מקרה נפוץ. כשאתם כותבים Dockerfile בעצמכם – נסו להקפיד ולספק הודעות שגיאה ברורות, אם חסר משתנה סביבה, למשל.
הפרמטר e- מאפשר לי לקבע ב container את ה env. variable שאני רוצה. ניתן לשרשר כמה env. variables שאני רוצה. שימו לב שעל שם ה image תמיד להופיע כפרמטר האחרון.
אפשר לראות שהפעם השרת מתחיל לרוץ… יוהו! הנה הפוסט אוטוטו נגמר.
בואו נאמת שאנו רואים שהקונטיינר רץ. רק עוד שניה אחת… שניה, יש לי בעיה! הרצת השרת "תפסה" לי את ה console. אני מנסה להקיש על Z^ – ללא הצלחה. גם C^ לא עוזר.
יש שרתים שלא מאזינים ל C^ (סיגנל INT) אבל מאזינים ל \\^ (סיגנל QUIT) – אני יכול להרוג כך את הקונטיינר, אבל יש צורה יותר ״מנוהלת״ לעשות זאת.
כמו שחלק מסט הפקודות של ה Docker API מזכיר את git, חלק אחר שלו – מזכיר ניהול תהליכים בלינוקס. אני פותח חלון נוסף של Terminal (הנוכחי "תפוס") ומתחיל להקליד:
(לחצו להגדלה)
הפקודה docker ps דומה לפקודה ps – ומציגה את רשימת ה containers הרצים.
אני יכול לראות את ה container id (גם הוא hash באורך 256 בתים, כאן אנו רואים רק את התחילית)
אני רואה כמה זמן ה container חי, וכמה זמן הוא רץ (לא תמיד זה אותו הדבר).
לכל container שלא נתתי לו שם, Docker בוחר שם מחיבור אקראי של שתי מילים, לפעמים זה יוצא מצחיק. אם הייתי מריץ הרבה containers מאותו סוג על אותה המכונה – כנראה היה לי חשוב לתת שם בעצמי – אבל בינתיים ה container id מספיק לי.
אם אני רוצה לראות את הפקודה המלאה שהורצה (במקרה זה: docker-entrypoint.sh mysqld – כצפוי מה Dockerfile, אם תחשבו מעט), או את ה id המלא של ה container אני יכול להשתמש בפרמטר no-trunc– שיציג את כל הנתונים ולא "יחתוך" אותם.
פקודת docker stop היא השקולה ל kill. אני מספק את ה container id בכדי להצביע את מי יש לסגור.
עכשיו אני רואה שבאמת ה container נסגר ואיננו רץ עוד. אני יכול לקרוא ל docker ps -a ולראות גם containers שכבר נסגרו.
כברירת מחדל, Docker משאיר את ה mount (כלומר: ה mount הגבוה ביותר ב union mount, המוקצה ל container עבור כתיבה). פקודת docker stop עוצרת את ה container – אבל לא מוחקת את הנתונים שלו – וזה פרט חשוב.
זה אומר שאוכל לחזור ולהריץ את ה container הזה, מאותו state אחרון שהיה בעת הסגירה (נעשה זאת בהמשך הפוסט).
זה אומר שתוך כדי עבודה, מצטברים לי הרבה "states" של containers סגורים חסרי שימוש – וצריך מדי פעם לנקות אותם.
אפשר להשתמש ב docker ps -a -f status=exited על מנת להציג רק את הקונטיינרים שכבר לא רצים (אך השאירו שאריות, אחרת הם לא היו מופיעים בפקודה docker ps).
בקיצור: הפקודה (docker rm $(docker ps -a -q -f status=exited – תנקה את כל השאריות שנותרו. זהירות לא למחוק יותר מדי.
ניסיון שני
הפעם נשתמש בפרמטר d- על מנת להריץ את הקונטיינר ברקע, כמו שמתאים לתהליך שהוא "שרת" (שזמן הריצה שלו – מתמשך). הנה אנחנו הולכים ומתמקצעים:
אני משתמש בפרמטר d- (קיצור של detached) על מנת להריץ את ה container ברקע. הפעם השתמשתי ב image id ולא ב name:tag – שתי הדרכים אפשריות.
כפלט לפעולה קיבלנו את ה container id (זהו ה hash הארוך). זה הנוהג ברוב הפקודות – וזו התנהגות שימושית למדי עבור כתיבת shell scripts.
איך אני יכול לראות מה קורה עם ה container? בעזרת פקודת ה docker logs (ברבים)
אני מפעיל את הפקודה כמה שניות מאוחר יותר – ורואה שהלוג אכן מתקדם (חתכתי את הטקסט בתמונה, כי הוא כבר נעשה ארוך).
יופי! הדברים באמת הולכים נהדר… נראה לי…
התחברות לשרת:
נתחיל לעבוד עם השרת. מכיוון שמדובר ב MySQL ואני על מק, רק טבעי שאשתמש בכלי בשם SequelPro [ג].
אני לוחץ על כפתור ה connect…. ו:
זה לא בסדר. מה ACCESS DENIED?
אני בודק שהקונטיינר רץ – אכן רץ. אני בודק הלוגים (פקודת docker logs) – ואין שום דבר. שום זכר לתקלה. אני מנסה ללחוץ עוד כמה פעמים על כפתור ה "Connect", אולי המחשב התבלבל – אבל לא. התקלה חוזרת על עצמה בעקביות.
למה זה קורה לי?
ספציפית יש פה מקרה קצת מבלבל: אני מריץ מקומית שרת MySQL 5.7, על הפורט ה default ועם משתמש בשם root – אבל לא ססמה מגוחכת כמו "123". בעצם ניסיתי להתחבר לשרת הזה – ונדחיתי כי הססמה הלא נכונה. אם לא היה לי את השרת MySQL המקומי מותקן, הייתי מקבל הודעה קצת יותר אינפורמטיבית בנוסח "Server not found".
אנחנו יודעים ש Docker לא מריץ באמת VM אלא תהליך מקומי עם מגבלות / אמצעי בידוד מוגברים. מה באמת יקרה אם אני מריץ גם MySQL 5.7 וגם כ Container שרת MySQL 8 על אותה המכונה? לאיזה שרת אני באמת אתחבר?
מה אתם חושבים?
כשאנחנו מבולבלים, זה זמן טוב ללכת ולהבין טיפה תאוריה.
אתם בוודאי זוכרים ש Docker היא טכנולוגיה "לינוקסית" המתבססת על טכנולוגיות ליבה של לינוקס (LXC, namespaces, cgroups וכו' [ב]). Docker לא באמת יכולה לרוץ ישירות על המק שלי, כי MacOS הוא וריאציה של Unix, לא Linux ואין לו את יכולות הליבה הנדרשות.
בכדי לרוץ על המק שלי, חבילת ה Docker Desktop for Mac כוללת VM המריץ לינוקס ועליו רץ Docker:
בעבר (כאשר היה צורך ב Docker Machine) היה עלי לכוון ל ip address של ה VM על מנת להתחבר ל Containers שאני מריץ.
היום ב Docker Desktop for Mac יש מיפוי אוטומטי של ports של ה containers ל localhost של ה host OS. הבעיה היחידה שיש לי היא ש port מספר 3306 כבר תפוס ע"י MySQL 5.7, ולכן המיפוי האוטומטי לא עובד.
האם עשינו תרגיל מוזר בכדי להריץ את Docker על המק? משהו חריג ששונה מאיך שנרוץ ב production? – לא ממש.
מכיוון שמטרת הפוסט היא להכיר Docker, ולא רק להריץ MySQL 8 מקומית, שווה להתייחס שניה לארכיטקטורה של Docker:
צהוב = תהליך, לבן = נתונים
הארכיטקטורה של Docker מתבסס/ת על 3 hosts:
ה Docker Client – ממנו שולטים על הנעשה.
ה Docker Host – המאחסן מקומית את ה images (להלן "local repository" – לא שם רשמי), ומריץ את ה containers. מכונת לינוקס.
ה Docker Registry – המאחסן ומשתף docker images בין docker hosts שונים.
במקרה שלנו:
Docker Client – ה host הוא המק שלי. משם אני מריץ את ה Docker CLI שהוא משמש כ client.
Docker Host – ה host הוא ה VM של לינוקס שרץ על המק. זה בעצם מיפוי די אמיתי לאיך שהדברים ירוצו גם בפרודקשיין.
ה Docker Registry – הוא Docker Hub ה"ציבורי".
כפי שניתן לראות בתרשים, הוא אינו חלק מתסריט של docker run – ולכן לא רלוונטי כרגע.
לסכם:
כשנרוץ ב production יהיה עלינו לעשות publish ל ports של ה container – על מנת לאפשר גישה מבחוץ. אין מיפוי פורטים אוטומטי.
הזכרנו את זה בתיאור של פקודת ה EXPOSE ב Dockerfile. חזרו והיזכרו.
מכיוון שה port כבר תפוס ב localhost – עלי לעשות מיפוי לפורט שונה ולחשוף אותו (גם נעשה בפקודת publish).
בקיצור: בכל מקרה נצטרך לעשות port publishing. הגיע הזמן.
בואו נעשה את זה!
אני מבצע publish, כאשר ה port הראשון שמופיע הוא זה של ה HostOS והשני הוא זה של ה container.
שווה לשים לב שפקודת P- (אות גדולה) עושה publish לכל ה exposed ports (ולאותו מספר port על ה HostOS).
אני יכול לראות את המיפוי מכל כתובת IP (סימון: 0.0.0.0) בפורט 53306 לפורט 3306 של הקונטיינר.
MySQL 8 חושף (expose) גם את פורט 33060 עבור עבודה ב X-Protocol המאפשר API דומה ל MongoDB. אין לנו כוונה להשתמש בו, ולכן אנו לא מפרסמים (publish) אותו.
זהו. אחרי כ"כ הרבה עבודה – מגיע לנו להתחבר כבר לקונטיינר שלנו. נשנה את הפורט ב SequelPro ל 55306, ונלחץ שוב על Connect על מנת להתחבר:
אז זהו. אפשר להכריז שהחיים אינם הוגנים! עבדנו קשה – ועדיין לא סיימנו.
יש לנו משוכה נוספת לעבור. לפחות הפעם השגיאה השתנתה – כלומר: התקדמנו.
אל ייאוש – עוד צעד אחד ומסיימים!
הבטחתי תסריט "עולם אמיתי" עם כמה תקלות – ואני מקווה שאני מקיים. המטרה: ללמוד על הדרך עבודה עם Docker.
אני מקווה שלא איבדתי 94% מהקוראים עד הנקודה הזו 😄
אני מחפש את הודעת השגיאה האחרונה ומוצאה פוסט ב Stackoverflow שמסביר את הבעיה וכמה דרכי פתרון. בגדול שיטת ה Authentication ברירת-המחדל של MySQL השתנתה בגרסה 8 (מה שקובע בהתקנה חדשה), והקליינט שלי SequelPro – לא תומך בשיטה הזו.
הפתרון שאני בוחר בו, הוא להפעיל את ה MySQL console ולשנות את שיטת ה Authentication למשתמש שלי. פעולה דיי פשוטה – אם היה מדובר בתהליך מקומי.
כאשר אתם עובדים עם Docker, תגיעו במוקדם או במאוחר לרגע שבו אתם צריכים לעשות "SSH לקונטיינר" ולשנות משהו. זה בלתי נמנע.
בעבר זה היה דיי סיפור. היום זה כבר פשוט מאוד – אז בואו נהנה מההתקדמות שנעשתה ב Docker:
אני מוצא את ה container id של הקונטיינר שרץ.
הפקודה docker exec מריצה פקודה נתונה בתוך ה container. במקרה הזה, אני רוצה להריץ bash ולעבוד כפי שאני רגיל – אבל ב console של ה container.
הפרמטר t- (קיצור של tty שהוא קיצור של יוניקס ל Terminal; אל תלמדו מיוניקס איך לבחור קיצורים!!) אומר שאנו רוצים לעבוד עם פרוטוקול של טרמינל, שמבוסס input/output טקסטואלי, אבל מממש עוד כמה פקודות i/o נוספות (ioctls, למשל הסיגנלים).
למען הדיוק: ה console הוא מימוש של פרוטוקול ה terminal, ו shell הוא המפרשן של ה console לפקודות. פעמים רבות אנו משתמשים ב terminal/shell/console כשמות נרדפים לאותו הדבר – אבל זה לא מדויק.
הפרמטר i- (בקיצור interactive) שומר את ה STDIN שלנו פתוח לאורך כל זמן הריצה.
נקצר ונאמר שברגע שאנו רוצים לעבוד עם console (כמו bash), יש להשתמש בצמד הפרמטרים it- אחרת ייתכן וניתקל בהתנהגות בלתי צפויה.
הנה נכנסתי ל console ואני יכול לעבוד. אני רוצה לקרוא לפקודה ll ולראות את רשימת הקבצים, אבל ברור לי שהיא לא תהיה זמינה בהפצה מינימלית של לינוקס – ולכן אני קורא ל ls -lah הבסיסית יותר (והשקולה). עובד.
עכשיו שאני ב console, אני יכול להחיל את הפתרון שמצאתי ב Stackoverflow:
exit ראשון יוצא מה MySQL console, ו exit שני יוצא מה bash – ומחזיר אותי ל Host OS console.
אני מנסה, ומצליח הפעם להתחבר ל MySQL 8 שרץ על הקונטיינר.
אני יכול להתחיל ולהתנסות בפיצ'רים של MySQL 8! איזה כיף!
הפעולה שביצעתי בכדי לאפשר את החיבור היא אמנם פשוטה, אבל עדיין נדרשת.
כפי שדיברנו, ה state של ה container נשמר גם אחרי שהוא נסגר. אני יכול לסגור את ה MySQL8, ואז להתחיל אותו מחדש – כאשר ה"תיקון" כבר מיושם בקונטיינר: בעזרת docker ps -a אני אמצא containers שנסגרו, ובעזרת docker start – אני יכול להריץ container הספציפי מהנקודה שבה נעצר.
אחרית דבר
נניח שאני רוצה להריץ כמה containers של MySQL8, עם נתונים שונים וכו'. האם אצטרך כל פעם לבצע את "התיקון" בצורה ידנית?
לא כ"כ מתחשק לי. אני רוצה לשמור את השינוי שביצעתי.
זוכרים שהוספנו Layers ל Image ב Dockerfile בעזרת פקודות RUN/ADD/COPY?
אז יש עוד דרך לייצר Layer בצורה דינאמית יותר. אני יכול לקחת את ה layer/mount העליון ביותר, זה של הקונטיינר – וליצור ממנו Layer חדש (ומכאן: image חדש). לפקודה הזו קוראים docker commit – והנה אני משתמש בה על מנת לשמור את השינויים שעשיתי בהגדרות ה authentication של משתמש ה root ב container שלי….
מלבד החיסרון הברור של פקודת docker commit שאין תיעוד (כמו ב Dockerfile) של מה באמת נעשה בה, ואין יכולת לחזור ולשנות נקודתית חלק ממה שהיא עושה – זה עדיין כלי שימושי.
האמת שלמקרה שלנו, הדרך הנכונה ביותר היא לבנות dockerfile שמוסיף את השינוי הקטן. בסה"כ אנו מריצים (RUN) עוד פקודה – ואני משוכנע שאתם כבר יכולים לעשות זאת לבד.
בשל ההתמכרות הקטנה שלי בפוסט לרוח הטלנובלה הטורקית (ארוכה ומלאת אסונות) – אני דווקא רוצה להשתמש ב docker commit על מנת לעשות את השינוי הנ"ל.
אני יכול לעשות commit, ליצור image חדש, ובאמת לראות שיש layer חדש שמוסיף מעט גודל – ולהריץ אותו. אבל אבוי: כשאני מריץ את ה image החדש – יש לי עדיין בעיית authentication בחיבור.
לא שגיתי בצעדים. הכל נכון, לכאורה.
הבעיה (והפתרון) טמונים בעצם בשורה הזו ב Dockerfile שלנו:
למה? מה השורה הזו בעצם עושה?
נראה… זה נושא לפוסט המשך (אם יהיו לי הכוחות. בלי נדר!)
שיהיה בהצלחה!
—-
[א] ביחד עם Serverless – נושא שכתבתי עליו עוד לפני שהציף את הפיד מכל עבר
[ב] Docker עצמה היא טכנולוגיה שמשתנה תדיר – וזו אחת הביקורות נגדה. מי שעבר עם Docker ב 2015 ולמד את ה Internals, בוודאי יופתע שהרבה מאוד השתנה בכמה השנים שחלפו.
פקודות השתנו ונוספו, אני זוכר שרק לפני שנתיים – שנתיים וחצי עבדתי עם Docker על מק והיה Docker Machine שמריץ boot2docker. זה כבר לא נכון, וזה משנה את אופן החיבור ל container, וכמה פקודות שהכרתי – וכבר חסרות שימוש (לפחות בתצורה הזו).
מנגנונים וטכנולוגיות התחלפו: aufs הוחלפה ב overlayFS, אפילו מנגנון הליבה LXC (להלן: Linux Containers שהחל את כל המהומה) הוחלף במימוש בשם libcontainer, כעת הוא ככל הנראה רצים בכלל על containerd ו runc.
מצד אחד, דיי לא סטנדרטי להחליף את הבסיס שעליו אתה רץ פעמיים בכמה שנים – מצד שני אני יכול גם להבין את החברה מאחורי Docker שגילתה מה לא עובד שוב, וביצעה את השינויים הקשים הנדרשים על מנת לפתור בעיות יסוד, ולהישאר רלוונטית.
אני רוצה להאמין שהבגרות של Docker אכן מתרחשת, וניתן לצפות לפחות שינויים ופחות דרמטיים בשנתיים שלפנינו – מאשר בשנתיים שעברו.
[ג] בעת כתיבת הפוסט, הגרסה האחרונה של SequelPro אינה תומכת ב MySQL 8. כמה מביך! אני משתמש ב nightly build כבר כמה חודשים – והוא יציב למדי.
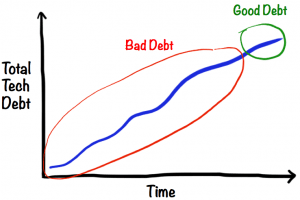
אני מניח שכולכם מכירים את המונח "חוב טכני" (Technical Debt), מונח שקבע Ward Cunningham בכדי לעזור ולחשוב על פשרות טכניות במערכת – שיש להן השפעות ארוכות טווח.
משמעות "חוב טכני" היא שפיתחנו פיצ'ר מסוים, וידענו שהפתרון הנכון ארכיטקטונית הוא פתרון X.
משיקולי זמנים (time-to-market, בעיקר), בחרנו ליישם פתרון נחות-ארכיטקטונית שנקרא לו x`.
את הפער בין הפתרון הרצוי ארכיטקטונית X לפתרון המצוי x` מתארים כחוב שיש להחזיר "למערכת". כמו חוב לבנק – הוא צובר "ריבית" בדמות פיתוח יקר יותר של הפיצ'רים הבאים, שייקח יותר זמן לפתח – בגלל קיצור הדרך שלקחנו.
למשל: בפיצר מסוים, במקום ליצור טבלה חדשה בבסיס הנתונים המתארת בצורה מדויקת את אופי האובייקט o, החלטנו "להלביש" את קיום האובייקט o על טבלה קיימת. שחררו את הפיצ'ר מהר יותר – אבל יצרנו עיוות שעכשיו בפיצ'רים חדשים נצטרך לעשות עבודה נוספת / לפתור חוסרי-התאמה חדשים בתוך המערכת, כי לא עשינו את ה"פתרון הנכון".
למטאפורה של "חוב טכני" יש כמה צדדים מדויקים יותר, ומדויקים פחות:
מתאר יפה את המצב:
לחוב טכני יש "עלות" או "ריבית" שתכביד עלינו ונשלם עליה – עד אשר החוב יוחזר.
בחוב טכני יש משהו גם חיובי: פעמים רבות נכון לביזנס לעשות פשרה מידית בכדי להשיג תוצאה מידית. הדבר טבעי במיוחד לשוק האמריקאי שם צמיחה של חברות היא מבוססת חובות – וזה מודל שמצליח.
לא מתאר בצורה טובה:
חוב כספי הוא מספרי וקל לחשב אותו: בדולרים. חוב טכני הוא לא מדויק, לא ניתן ממש להעריך את העלות "להחזיר אותו" וגם לא ניתן למדוד במדויק את הנזק שהוא גורם לאורך זמן.
פריון מפתחים – הוא נושא לא-מדויק מטבעו.
חוב כספי, גדול ככל שיהיה אפשר להחזיר ברגע אחד. חוב טכני משמעותי יוחזר על ידי עבודה ארוכה, של המשאבים הקיימים.
יש כלים (למשל: SonarQube) שמנסים לתת מספר (זמן / דולרים) שיתאר את החוב הטכני של המערכת. קצרה היריעה מלפרט עד כמה ההערכות הללו הן סתמיות…
אין לי מטאפורה טובה יותר בכל מימד, אבל אולי מטאפורה של סמי-מרץ – היא מטאפורה משלימה למטאפורה של "חוב טכני".
אם אנחנו ספורטאים, ואנחנו בתחרות – נסכים לעשות הרבה בכדי לעמוד יפה בתחרות.
רופאים אומרים שהרבה קפה הוא דבר מזיק – אבל אני בטוח שיש כמה ספורטאים שהוא עוזר להם. אי אפשר לנבא ולמדוד את התוצאות השליליות – זה נושא מורכב ולא מדויק. הרבה ספורטאים הצליחו עם כמה התנהגויות שנחשבות לא בריאות (ספורט תחרותי, בכלל – הוא דבר לא בריא לגוף…) וחיו לאורך שנים.
יש גם סמים קשים יותר, עם תמורה קצרת טווח חזקה יותר – אבל גם סיכון לנזקים חמורים בהרבה.
במידה והחלטנו להפסיק להשתמש בסמי-מרץ קשים, תהליך השיקום עומד להיות ארוך וכואב – בדומה מאוד לחוב טכני עמוק ומשמעותי… זה לא נגמר ביום, אלא זה מסע מפרך וכואב שאי אפשר לדעת מתי יגמר.
קצת מעבר להגדרה היבשה
בואו ננסה לדייק כמה נקודות, מעבר להגדרה הפשוטה של חוב טכני:
לא תמיד אנחנו צודקים בהערכה שארכיטקטורה X עדיפה על ארכיטקטורה x`.
לעתים אנו מבצעים הערכות-יתר לחשיבות של אופן מימוש מסוים.
לפעמים הנסיבות משתנות באופן בלתי-צפוי: דרישה או צורך באובייקט מרכזי במערכת מתבטל או משתנה, ופתאום x` הופכת לארכיטקטורה עדיפה על X. זה לא קורה כל יום, אבל זה קורה.
גם כאשר ארכיטקטורה X עדיפה – לא תמיד היתרון שלה הוא משמעותי או מוצדק.
יכול להיות ש"לתקן" את החוב הטכני יעלה יותר מכל מחיר שנשלם אי פעם בחיי המערכת, בשל העיוותים שיצר. דוגמה קלאסית: שמות של עמודת בבסיס הנתונים: השם הלא-נכון מציק, אבל שינוי עשוי להיות יקר מאוד לביצוע.
הצהרה על חוב טכני הוא לעתים "קלף מיקוח" בניסיון להשפיע על אחרים בכדי להסכים דרך פעולה שאני רוצה לקדם. מתוך רצון להשפיע – אני עלול להגזים (ויותר) בתיאור החוב הטכני.
"חוב טכני" הוא טיעון של אנשי-טכנולוגיה, לא אנשי ביזנס
אחד מסוגי החובות הטכניים הנפוצים והמזיקים ביותר הוא הנדסת-יתר (over-engineering). הרבה יותר קשה להתקדם ולפתח פ'צרים עם 6 שכבות הפשטה – אם נדרשות רק 2.
במקרים של הנדסת-יתר לרוב לא נשמע את הקול שאומר "זהו חוב טכני. אנחנו חייבים להחזיר אותו (להסיר רמות הפשטה) בכדי להתקדם יותר מהר", אבל הרבה פעמים – זה בדיוק המצב.
וריאציה אחרת היא סיבוך המערכת ויצירת חוב-טכני, דווקא תחת ה ticket של "החזרת חוב טכני".
לא תמיד מתן אשראי למי שמוכן "להחזיר חוב טכני" – היא פעולה נכונה. עולם התוכנה הוא אכן מורכב: על מנת לפעול נכון חשוב לצלול ולהבין את הדברים.
למרות ערימת ההסתייגויות למעלה, חוב טכני עמוק הוא דבר הרסני למוצר ולחברה
חובות טכניים עמוקים, בליבת המוצר והמודל שלו – עשויים לעשות את ההבדל בין מוצר מצליח לכושל.
חוב טכני – אבוי! מקור: וויקיפדיה
חובות טכניים, הם לא אחידים, ולא כדאי להתייחס אליהם ככאלו. אם ניזכר לרגע בכמה חובות טכניים מפורסמים:
באג 2000 (Y2K) – אבותינו חסכו בשטח האחסון ולכן מידלו שנה כ-2 ספרות ("95") ולא כ-4 ספרות ("1995"). מה קורה כאשר מגיעה שנת 2000? מיון? בדיקה איזה תאריך קדם לשני? – בלאגן.
החוב הטכני קיבל פרופיל תקשורתי עולמי – והיה סיכון ברור ומידי. למרות נבואות-זעם על עולם לא-מתפקד, הוא תוקן בזמן (ובמחיר עצום), ועברנו לשנות ה-2000 בשלום.
Referer של HTTP – בתקן ה HTTP הוגדר header חשוב בשם Referrer. בתקן נפלה שגיאת כתיב (נכתב: "Referer") אך עד שגילו את הטעות כבר היו עשרות מפתחים ואולי מאות מפתחים כבר מימשו את שגיאת הכתיב. מלבד בדיחה על בקשה שהוגשה למילון אוקסופרד לתקן את הטעות במילון (שם יותר קל לתקן) – לא נעשה ניסיון אמיתי לתקן את שגיאת הכתיב. זו דוגמה טובה לחוב טכני שהוא טעות – אך לא משתלם לתקן. ככל שהזמן עובר – זה הופך למשתלם אפילו פחות.
דוגמה נוספת למשהו שאולי היה רצוי לתקן, אך בלתי-אפשרי בעליל הוא שיטת המדידה האימפריאלית הנהוגה בארה"ב. מדוע צריך לעבוד עם המרות לא נוחות כמו "מייל הוא 5280 רגל"? האם השיטה המטרית היא לא נוחה יותר? – כנראה שכן, אבל כבר מאוחר מדי.
להתחיל מערכת חדשה ללא בדיקות-יחידה / CI-CD אמיתי / תשתית לוגים סבירה – היא דוגמה לחוב טכני הרסני. אלו דברים שאם לא מתחילים איתם, הקושי להוסיף אותם מאוחר יותר הוא חסר תקדים. הייתי שותף להשקעה של שנות-אדם רבות בניסיון להחיל בדיקות יחידה, CI אמיתי, או תשתיות לוגים במספר מערכות שונות ש"גררו כמה שנים בלי". על אף מאמצים הרואיים, מגובי-הנהלה גבוהה – לא זכיתי לחזות במקרה שהייתי מגדיר כמוצלח.
רק להסיר ספק: קיום כל אחד מהשלושה הנ"ל הוא כלי productivity חשוב מאוד לארגון פיתוח / למערכת.
ה"טורנדו" של הסתבכות המערכת.
למי שלא חווה – זו עשויה להראות כמו דאגה מופרזת, אך למי שחווה הגעה לאזור האדום או הסגול – זו חוויה מדכאת, שלא תרצו לחזור אליה…
איך (לא) מחזירים חוב טכני?
כפי שראינו, חובות טכניים הם שונים זה מזה – ולא נכון להתייחס אליהם כמקשה אחידה.
אני יכול לעסוק בהגדרות שונות ומשונות לחובות טכניים, וסיווגים שונים כיצד הם נוצרים.
זה לא מעניין מבחינתי.
בכל מערכת יש סדרה אינסופית (מבחינה מעשית) של חובות טכניים: כמה מהותיים, קצת יותר בינוניים, והמון פצפונים. ככל שנתקדם – ייווצרו עוד.
הניסיון "להחזיר את החוב עד תומו" – הוא נאיבי וחסר-בסיס.
הזדמן לי פעם לעבוד בארגון גדול שבו ניתנה הזדמנות נדירה להשקיע חצי שנה של כל גוף הפיתוח על מנת לנקות "חובות טכניים" ממוצר שלא היה חריג מבחינת החובות הטכניים שבו (אני יודע לומר בדיעבד).
תוך כדי פתרון חובות טכניים מסוימים – נוצרו גם אחרים.
בשום רגע, לא הייתה הסכמה מלאה מהו חוב טכני ומה לא. עשרה יהודים = מאה דעות.
זה היה פשוט תרגיל נפלא ביתירות הנדסית. לאחר חצי-שנה המוצר שוחרר לשוק – שם זכה לכישלון מסחרי נחרץ, והוא נסגר זמן קצר לאחר מכן.
את החובות הטכניים המשמעותיים – לא יגלו לכם כלי בדיקה אוטומטיים (כגון Static Analysis tools): הם יגדלו את הקטנים עד הפצפונים – והמון מהם, אך גם לא את כולם.
החובות הטכניים הגדולים הם דברים ש"עקומים" במערכת, בארכיטקטורה שלה, בתהליכים שלה, ובתיאור המציאות שלה. אנחנו נלמד עליהם ממי שמכיר היטב את המערכת ועובד איתה ביום-יום, אם כי לעתים זקוקים לעתים לנקודת מבט של מישהו שעדיין לא התרגל לרעות החולות – ויכול להצביע עליהן, ועל האפשרות לעשות את הדברים טוב יותר.
בחובות הטכניים הגדולים לא קשה כ"כ לשכנע את ההנהלה – כי אפשר להסביר להם מה עובד לא בסדר, ויש לכך לרוב כמה עדויות.
הרבה פעמים קשה לשכנע בקיום חוב טכני משמעותי לפני שהוא מתחיל לתת את אותותיו, והרבה יותר קל לשכנע אחרי שנזק הולך ונגרם. יש הוכחות.
בתפיסת ה Lean Architecture, חשוב מאוד להבין את הדינמיקה הזו.
כאשר אנו מזהים חוב טכני שהולך להיות מיושם, שווה לעשות מאמץ ולנסות למנוע אותו מבעוד-מועד.
לא תמיד נצליח לשכנע שזה אכן מדובר בחוב טכני משמעותי – לפעמים פשוט לא תהיה הסכמה על קיומו של החוב או משמעותו. בפעמים אחרות, תהיה הסכמה – אך עדיין החלטה לקחת אותו ולהתקדם הלאה.
גם במקרים כאלו, לא כדאי להתייאש או לריב עם כל הארגון, על מה שהארגון כרגע לא מסוגל לראות.
עומדים לרשותנו עדיין שני כלים:
לנסות להשפיע על סדר הפעולות, כך שחוב הטכני ייחשף ויוכח מוקדם יותר (ובשאיפה: עם נזק מינימלי).
להשתיל "מנופים" לתיקון החוב: עדיף לתקן בדיעבד בקלות רבה יותר – מאשר ל"הילחם בטחנות רוח" ללא הצלחה.
להזכיר: גם אנו לעתים לא מבינים נכון את הדברים. ומה אם אנחנו טועים?
לפעמים, ניסיונות חוזרים ונשנים להתמודד עם חוב טכני מהותי – שהארגון מסביב לא מסכים להכיר בו הוא סימן שכדאי להחליף ארגון. זה עשוי להיות טוב לשני הצדדים – ובלי לקבוע מי באמת צודק. בסיבוב הבא (ב-2 הצדדים), כנראה שתהיה הפקת לקחים.
סיווג אחד (מני רבים) של סוגים שונים של חובות טכניים ומקורותיהם. מקור: Martin Fowler
כדאי מאוד להימנע ככל האפשר מחובות טכניים משמעותיים ומיותרים. סיווג המקור – פחות חשוב.
איך (כן) מחזירים חוב טכני?
בגדול, יש שלושה אלמנטים חשובים בטיפול בחוב טכני:
זיהוי החוב הטכני, וסיווגו ע"פ השפעה על המערכת / הארגון.
שיקוף ושיתוף החוב הטכני, לחלקים שונים בארגון.
מציאת המנגנון הארגוני לצמצום חוב טכני.
חוב טכני תמיד יגדל (עוד קוד נוסף, הביזנס משתנה, המערכת גדלה ונעשית מורכבת, הקוד מתיישן ו"נרקב") – וחשוב להוריד אותו בקצב שקול לגדילה – על מנת, לפחות, להישאר במקום.
כארכיטקטים, או מובילים טכניים בארגון, עליכם להתכונן כ"שבט של ציידים": להתכונן לשעת כושר, וכשהיא מגיעה – לנצל ממנה את המיטב.
הציד הוא דליל רוב ימות השנה, וחשוב להתמודד עם המחסור.
אבל מידי פעם, יעבור באזור עדר גדול של בפאלו נודד. שבט שמתחיל לפעול רק כאשר העדר כבר הגיע – לא ישרוד לאורך זמן. עליו להיות מוכן ליום הזה, ולנצל את ההזדמנות ברגע שהגיעה – עד תום.
באופן דומה, הזדמנויות לצמצום החוב הטכני, לא נופלות מהשמיים, ולא כל ימות השנה. עליכם להיות מוכנים עם תוכנית אופרטיבית – שכאשר יש הזדמנות ("אוי – יש לנו מפתח פנוי בחודש הקרוב"), אנחנו יודעים בדיוק מה לעשות, יש לנו מגוון אפשרויות – ואנו יכולים להפיק מההזדמנות את המירב.
ניהול "רשימת בעיות":
כל פעם שאני מבין שיש פה חוב טכני בעייתי שארגון סובל בגללו (או שעומד להיות) – אני מוסיף אותו לרשימה.
מדי פעם בצורה פרואקטיבית – אני יושב עם המפתחים הוותיקים, מעדכן ומתקנן את הרשימה.
את הרשימה חשוב לתעדף. אם יש לרשות הארגון מפתח זמין לחודש, עדיף מאוד שיפתור בעיה חמורה שהנזק ממנה ברור – מאשר "לסדר קצת את הקוד". יצירת Impact חיובי הוא גם מפתח על מנת שהארגון ימשיך וירצה להשקיע בצמצום חובות טכניים בעתיד.
אם יש בעיה ללא פתרון – זה לא עוזר. לפחות למספיק מהבעיות – חשוב שיהיה פתרון ידוע. אם צריך להשקיע ב Design – השקיעו מדגמית בכמה עניינים חשובים באזורים שונים. אי אפשר לדעת באיזה אזור של המערכת "יעבור עדר הבאפלו".
השיקוף של הבעיות – הוא חשוב מאוד גם כן. גם לצד ההנהלה, וגם לצד המפתחים:
אם ההנהלה לא יודעת שיש בעיות חמורות, זה לא הוגן ולא אחראי. היא לא תדע להקצות את המשאבים (שתמיד נמצאים במחסור) בכדי להתמודד עם הבעיה.
אם המפתחים לא מבינים שדברים מסוימים מהווים בעיה חמורה – הם לא ידעו לצמצם ולהגביל את הבעיה. מכירים את ה Anti-Pattern של "שכפול Anti-Patterns במערכת"?
אם אתם לא מבינים את הבעיה, איך המפתחים לא יתקנו אתכם ויסבירו לכם – אם לא תדברו איתם על זה. תנו להם הזדמנות לתקן אתכם, ולחסוך לכם חוסר-נעימות.
מציאת המנגנון הארגוני לטיפול בבעיה:
זה לפעמים החלק הכי קשה, ואני מקווה עבורכם שזו לא "הבעיה שעל כתפכם בלבד".
בחלק הבא (והאחרון) נעסוק בה קצת יותר בהרחבה.
רשימה לדוגמה של חובות טכניים שיש לפתור במערכת.
הרשימה רק תלך ותתארך, אז חשוב כל הזמן לפתור בעיות, לבדוק אלו עדיין רלוונטיות, ולתעדף.
מציאת המנגנון הארגוני לצמצום חובות טכניים
תפיסה נפוצה (נתקלתי בה כבר מספר פעמים) היא שיש להקצות זמן נתון (הכלל המקובל: כ 20% בזמן העבודה) לצמצום חובות טכניים.
גישת הצוות:
ברוח ה empowerment (עניין מבורך) מורים לכל צוות להקצות את הזמן שלו – מבלי שישתף את שאר הארגון כיצד הוא מנצל אותו.
כאשר המשאבים הם מקומיים (ברמת הצוות) – קשה עד בלתי אפשרי לפתור את הבעיות הגדולות.
כבר נתקלתי לא-פעם בצוותים שניצלו את רוב הזמן שניתן להם בכדי לנסות טכנולוגיות "חדשות ומגניבות" שלא עשו שום השפעה חיובית משמעותית על המערכת או הארגון. זה בטח טוב לריצוי עובדים – ברמה כלשהי.
הגישה הגלובאלית:
גם כאשר הזמן המוקצה לצמצום חובות טכניים הוא "גלובאלי" (משותף לכל ארגון הפיתוח) – חשוב מאוד כיצד הוא מתוקשר ומנוהל.
לא פעם ראיתי שהוא תוקשר בצורה כזו שאנשי המוצר הרגישו ש"גוזלים מהם מזמן הפיתוח, בלי הצדקה" (מילים שלי).
למשל: בכל תוכניות העבודה מציגים 20% זמן טכני – ואנשי המוצר מתחלקים הזמן הנותר. זה נשמע כמו רעיון טוב על מנת להסביר מדוע לא כל המפתחים עובדים כל הזמן על משימות מוצר, אבל עלול בקלות לגרום לתחושה של אובדן משאבים מצד אנשי המוצר.
תגובה טיפוסית לתחושה כזו, היא לנסות ולהעמיס על "זמן החזרת החוב הטכני" כל מאמץ אפשרי: תיקוני באגים, כתיבת בדיקות-יחידה, או קבלת חובות טכניים במופגן – בידיעה שהם יכוסו מתקציב אחר. זה אף פעם לא מתחיל כך, אך זה בקלות עלול להתדרדר לשם לאורך הזמן. משאבי-פיתוח הם משאב יקר ערך בארגונים, ורק טבעי שברגע שיש "תקציב חדש" – רבים ינסו לנגוס בנתח ממנו להשגת היעדים הארגוניים שהם אמונים עליהם.
יתירות בפיתוח:
רעיון אחד שנתקלתי בו הוא הרעיון שיתירות בפיתוח (כלומר: יש יותר מפתחים ממה שצריך) – יאפשר לטפל בחוב טכני בצורה טבעית. זה רעיון הגיוני לוגית – אך לא ראיתי אותו אף פעם קורה בפועל:
כל עוד איש מוצר יכול, בעזרת מצגת שהכין בשעתיים, ליצר עבודה לצוות פיתוח לחודשיים – לא יהיה לעולם זמן פיתוח "יתיר".
עוד נקודת מפתח והיא יוקרה של צמצום חובות טכניים בארגון: כל עוד מירב מקבלי-ההחלטות בארגון מעריכים יותר פיצ'ר חדש מתיקון של חובות טכניים – הזמן שהוקצה להתמודדות עם חובות טכניים "יזלוג" לכיוון פיתוח פיצ'רים. כאן הפתרון הוא שיקוף יעיל של הבעיות הטכניות (עניין שהזכרנו קודם):
חשוב שלמקבלי ההחלטות יהיה מושג על בעיות קיימות – ומה ההשפעה השלילית שלהן. הם לא יוכלו להבין את רוב הבעיות הטכניות – אבל כמה דוגמאות משמעותיות עשויות לעשות את ההבדל בתפיסה.
חשוב שמקבלי ההחלטות יראו גם שבעיות נפתרות, או לפחות יחושו בצורה כלשהי שיש תרומה לחברה מתוך עיסוק בצמצום חובות טכניים (למשל: לשתף מכתב תודה של יחידה אחרת בארגון שסבלה מבעיה כלשהי).
שיקוף אפשרי בעיקר לבעיות שנוגעות גם לביזנס בצורה ישירה (downtime, אטיות, פגעי-אבטחה), וחשוב לנצל תיקון של בעיות על מנת להדגים את החשיבות במערכת שלא רק כתובה – אלא גם כתובה נכון.
הבחנה חשובה היא בין חוב טכני "טוב" ו"רע":
חוב טכני קצר טווח – הוא פעמים רבות שימושי ומועיל. למשל: מיקוד בשחרור מוקדם ולמידה.
חוב טכני משמעותי ושנמשך לאורך זמן – הוא לרוב "רע"
לפעול במהירות ובנחישות:
גישה שעשויה לעבוד עבור מגוון מקרים היא ניהול פנימי של החוב הטכני בתוך הפיתוח: מיד בסוף הפיצ'ר מקדישים כמה ימים על מנת "לנקות חובות" ולשפר את הקוד היכן שצריך.
לפעמים זה חצי יום – ולפעמים שבועיים.
לא מדווחים על סיום המשימה עד שלא מסיימים את החובות הטכניים המידיים. מסבירים שיש עוד כמה צעדים טכניים נדרשים לסיום המשימה.
נקודת מפתח להצלחה היא מחויבות עמוקה של מנהלי הפיתוח, והיכולת שלהם לעמוד בלחצים מצד אנשי המוצר. אף אחד לא שמח לשמוח על פיצ'ר שמתעכב בשבועיים (גם אם שוחרר כרגע, ויש רק עוד סדרת תיקונים נדרשת).
בארגונים מסוימים – עדיף לא לשקף לאנשי המוצר לאן הזמן בדיוק הולך. אולי רק בצורה ראקטיבית לשאלות.
בארגונים שבהם יש יותר אמון הדדי – שווה לשקף, אבל להיזהר ולהסביר את ההשקעה בצורה שתבנה אמון עם היחידות העסקיות.
צוות לצמצום חובות טכניים:
בגלל שהבעיות לעתים דורשות השקעה ארוכה, ומומחיות – אחד המודלים הוא לייצר "צוות תשתיות" או צוות שיתקן בעיות במערכת.
למי שיש לו ניסיון בתוכנה, הרעיון הזה עשוי להישמע מופרך כמו הרעיון שעובדים outsource יבואו וינקו את הקוד (יבצעו refactoring) עבור המתכנתים של הארגון. אבל היי – גם דבר כזה קיים.
בעיה עיקרית במודל הזה היא שחיקה של האנשים שבצוות.
בעיה שניה היא שחובות טכניים רבים הם בליבת המודל הלוגי של המערכת. בלי היכרות אינטימית – לנסות לכתוב קוד טוב יותר זו משימה כמעט בלתי-אפשרית.
יתרה מכך, גם מי שמכיר את המערכת מצוין ועסוק במשימות טכניות לאורך זמן ארוך – יאבד את הקשר עם פרטי המערכת, שמשתנה כל הזמן.
אחת הווריאציות היותר הגיוניות לטעמי, היא שצוותים "משאילים" אנשים לצוות לצורך משימות של צמצום חוב טכני – ובסיום המשימה האדם חוזר לצוות.
דרך ההתנהלות של הצוות שלא כפופים למחזור מוצרי (אם עובדים ב SCRUM) ותמיכה של אנשים טכניים חזקים – יכולה דווקא לעזור, ולייצר גיוון למי שמצטרף זמנית לכזה צוות.
גם הקצאת המשאבים – היא קלה יותר לניהול, כאשר מדובר בצוות.
צמצום חוב טכני – כאירוע: מודל אחר שיכול לעבוד הוא לרכז מאמץ של יחידה גדולה, או כל הפיתוח – על מנת לצמצם במרוכז חובות טכניים.
וריאציה אחת ששמעתי עליה, היא חברה שמקדישה 3 ימים כל תקופה מסוימת – על מנת לשפר ולהעשיר את המערכת בבדיקות אוטומטיות (בדיקות יחידה, בדיקות אינטגרציה, וכו' – בדיקות שמפתחים כותבים). ע"פ הסיפור – זה עבד דיי טוב.
וריאציה שניסינו לאחרונה בחברה הנוכחית שאני עובד בה (Next-Insurance) היא להפעיל את כל הפיתוח למשך שבועיים – על מנת להתמודד עם רשימת בעיות שהוכנה ותועדפה מראש.
הזמן הארוך יחסית – מאפשר לפתור בעיות שהן לא רק פצפונות / נקודתיות.
האמירה שיש השקעה משמעותית באיכות הטכנית של המערכת – משדרת מסר חשוב גם למתכנתים, וגם לשאר הארגון
אני אישית, מאוד נהנה מתקופות כאלו.
בכל מקרה, חשוב לתת את הבמה הראויה לתיקון של חובות טכניים משמעותיים – להלל ולהעריך בפומבי את מי שפתר בעיה מהותית. ההוקרה גם מצדיקה עבודה שהיא פעמים רבות קשה ומתישה, וגם משדרת בארגון שאנו מעריכים הנדסה טובה – ולא רק עמידה ביעדים ("בכל מחיר").
סיכום
שוב אמרתי לעצמי, שאבחר נושא קצרצר לפוסט, ואכתוב משהו באורך 4 tweets לכל היותר. לא הצלחתי – היה לי יותר מה לומר משחשבתי.
כמה דגשים שחשוב לי שלא תצאו מקריאת הפוסט בלעדיהם:
נקודת האופטימום הארגונית היא בהחלט לא "אפס חוב טכני", או לפחות לא בתפיסה המקובלת. "מקסימום הנדסה" – היא לא מקום טוב לביזנס או למערכת חיה להיות בו. חשוב לקחת כמה סיכונים, ולהתקדם בקצב טוב.
"חוב טכני" הוא מושג מאוד סובייקטיבי. בהגדרה מסוימת – רעיון החוב הטכני עשוי להתרגם לאיסוף עבודה חסרת חשיבות.
חשוב חשוב חשוב להתמקד בטיפול בחוב טכני שיש לו השפעה חיובית מורגשת (Impact).
לעתים יש חוב טכני (Design, שמות של משתנים) שעצם קיומו מציק לנו כמהנדסים, אבל אין לו חשיבות לפעילות המערכת.
הייתי משקיע מעט עבודה (low hanging fruits) עבור ההרגשה הטובה, בנוסח "החלונות השבורים" (לשמר אווירה של אכפתיות במערכת)
הייתי מתאמץ לקבל גם אלמנטים לא-אלגנטיים במערכת, ואפילו צורמים – כל עוד העלות / תועלת לפתור אותם היא לא סבירה. למשל: עניין ה referer ב HTTP.
מערכות מתחדשות מטבען. אם תתעדו ("רשימה") ותשתפו ("שיקוף") בבעיה – יש סיכוי טוב שבשכתוב הבא המצב יהיה טוב יותר.
הכי מעצבן זה לראות קוד ששוכתב ושימר חובות טכניים מהותיים – מחוסר הבנה.
חוב טכני לא צריך להיפתר לחלוטין. הורדה של בעיה מרמת Critical לרמת Medium – עשויה להיות התקדמות חשובה ומספיקה.
בפעם הבאה שנרצה לשפר משהו, כנראה שנבחר בעיה קריטית אחרת – על פני העלמה של בעיה בעלת חומרה בינונית.
למרות ש"חוב טכני" הוא עניין בד"כ עניין טכני וטכנולוגי – מציאת המנגנון לצמצום חובות טכניים הוא בעיקר ארגוני. עבדו עם ההנהלה ומי שיכול לקדם דברים בארגון – לא רק עם מקצועני התוכנה.
כמו בפוסטים רבים אחרים, אני רוצה לקחת נושא בסיסי – ולהיכנס קצת יותר לעומק.
הפעם: Transactions בבסיסי נתונים, וספציפית – ב MySQL.
בפוסט הזה כשאני מדבר על MySQL הכוונה היא רק למנוע האחסון InnoDB.
כולנו, אני מניח, מכירים בסיסי-נתונים רלציוניים: על כך שהם ACID, ועל כך שיש להם טרנזקציות.
איך משתמשים בטרנזקציה? בבסיס, באופן הבא:
START TRANSACTION;
— do something
COMMIT; — or: ROLLBACK;
אני מניח שאת זה כולם יודעים – אבל זו רק ההתחלה.
בואו נחזור ונדבר מתי להשתמש בטרנזקציות, ולמה יש לשים לב.
למה להשתמש בטרנזקציות?
כיום, טרנזקציות הוא דבר "לא-קולי" ("not cool").
לפני כעשור, פרצו לחיינו כסערה בסיסי הנתונים הלא-רלציוניים [ג] (NoSQL) והם היו הדבר הכי קולי עלי האדמות, לפחות. בסיסי הנתונים הללו עבדו ללא טרנזקציות, והם הסבירו לנו שוב ושוב מדוע טרנזקציות הן האויב של ה scalability (שזה עדיין נכון, בגדול).
מאז השוק התפכח והבין שבסיסי-נתונים רלציוניים עדיין מאוד שימושיים ורלוונטיים.
מגמה שהתהפכה, היא שחלק מבסיסי-הנתונים הלא רציונליים דווקא החלו להוסיף יכולות ACID וטרנזקציות.
למה? כי זה שימושי.
כדאי שרוב העבודה תהיה ללא טרנזקציות, אך פה ושם – טקנזקציות הן חשובות מאוד.
עדיין, הקמפיין להשמצת הטרנזקציות היה יעיל יותר – והטרנזקציות נותרו חבוטות ודחויות על רצפת חדר-התכנון של ארגונים רבים.
ובכן:
טרנזקציות הן אויב ל Scalability (ברוב המקרים), וכאשר צריך הרבה Scalability – עלינו להימנע מהן.
גם במערכות המתמודדות עם Scalability, ישנם flows ותסריטים שעובדים ב volume נמוך יותר – ויש להם בעיות שטרנזקציות יכולות לפתור.
חטאנו (גם) בשנות האלפיים, ועשינו שימוש-יתר, ביכולות שונות של בסיסי-הנתונים הרלציוניים: כמו טרנזקציות, Foreign Keys, או Triggers. עדיין, בשימוש מידתי – אלו כלים שימושים שיכולים לפתור בעיות רבות.
הסיפור של Overselling של כלים וטכניקות, הוא לא מקרה יחידני. הוא קורה שוב ושוב, ויקרה שוב ושוב. תתרגלו.
טרנזקציות הן פעמים רבות, הכלי הנכון והטוב ביותר לפתור בעיות.
אם אתם מסוגלים להתגבר על הקושי שלא המציאו את הטרנזקציות בשנת 2018 בגוגל, והן לא מככבות במצעד ה"טכנולוגיות היפות והנכונות של 2019 [א]" – אז יש לכם סיכוי טוב להעשיר את סט הכלים שלכם בצורה מועילה.
נחזור לשאלה המקורית, שמסתבר שהיא לא טריוויאלית: "מדוע / מתי להשתמש בטרנזקציות"?
הנה שימושים מרכזיים לדוגמה:
אנו רוצים לעדכן שתיים (או יותר) טבלאות בבסיס הנתונים בצורה עקבית: שלא יוותר מצב שאחת מעודכנת, אבל של תקלה – השנייה לא עודכנה, ויש לנו אי-עקביות בנתונים / נתונים חסרים.
אנו רוצים לעדכן ערך בטבלה, בצורה עקבית ותחת racing condition אפשרי: שני threads (או מנגנון מקבילי אחר) רוצים לבצע שינוי שתלוי במצב הקיים – אבל ללא הגנה התוצאה יכולה להיות שגויה.
אנו רוצים להשתמש בבסיס-הנתונים כמגנון סנכרון פשוט בין כמה שרתים.
אין לנו מנגנון אחר, ובסיס-הנתונים הוא מספיק טוב למשימה.
שיפור ביצועים – זה נשמע לא אינטואטיבי, אבל במקרים מסוימים טרנזקציות דווקא יכולות לעזור לשפר ביצועים.
ביצוע שינוי בנתונים בצורה זהירה ומפוקחת – (בסביבת פרודקשיין, למשל). נבצע את השינוי, נבחן את השלכותיו, ורק אז נעשה commit.
לכאורה אפשר לחשוב (בתמימות) שלכל המקרים יש פתרון זהה. שבשימוש בפקודות START TRANSACTION … COMMIT – נפתרו בעיותינו. מובטח לנו שמה שציפינו, אכן יקרה, וללא תופעות לוואי מיותרות – כמובן.
הבעיה היא שבכדי להבטיח ACID, בסיס הנתונים משתמש בנעילות שפוגעות מאוד ביכולת לרוץ במקביל על אותם הנתונים.
ישנו Trade-off מאוד בסיסי פה: יותר בטיחות כנגד יותר מקביליות / ביצועים.
ברגע שעזבנו את מכונת המפתח-הבודד / קורס באוניברסיטה – חשוב לנו לבצע טרנזקציות עם מינימום השפעה על הסביבה.
ההשפעה בשלב הראשון על הביצועים (נניח: כמה עשרות אחוזים פחות פעולות בשנייה), אבל כאשר יש יותר מקביליות על אותם הנתונים – יכולות להיווצר נעילות של שניות רבות (כלומר: פגיעה חמורה ב latency של הבקשה) ו/או deadlock (או שבסיס הנתונים יתיר אותו במחיר דחיית אחת הטרנזקציות, או במקרים חמורים – יהיה עלינו לבצע את הפעולה הזו בעצמנו).
את ה tradeoff בין בטיחות למקביליות – בסיס הנתונים לא יודע לקחת עבורנו. הוא מספק לנו כמה נקודות בסיסיות על ציר ה tradeoff (להלן Isolation Levels), ועוד כמה כלים נוספים בכדי לדייק את המקום בו אנו רוצים להיות.
עלינו להבין אלו סיכונים אנו מוכנים לקחת לחוסר עקביות בנתונים, והיכן בעצם לא קיים סיכון ולכן ניתן להשתמש בפחות הגנות (ולאפשר יותר מקביליות).
ככל הניתן – עדיף להימנע משימוש בנעילות וטרנזקציות.
לעתים, אפשרי ונכון להתפשר על עקביות הנתונים (למשל: אירוע א מופיע לפני אירוע ב' למרות שבפועל הסדר היה הפוך. פעמים רבות, בהפרש של חלקיק שניה – זה לא משנה).
בפעמים אחרות – לא נכון להתפשר על עקביות או נכונות הנתונים, ועדיין נרצה לצמצם את ההגבלה על המקביליות.
אנחנו נראה שלשימוש בטנרזקציות יש השפעה שלילית אפשרית על הביצועים – גם כאשר שום טרנזקציה לא ״תקועה״ ומחכה למנעול.
זו הזדמנות טובה להזכיר את Amdahl's law המראה את הקשר בין החלק בפעולה שאינו מקבילי – לחסמים על מקביליות, לא משנה בכמה threads נשמש….
כדי להשלים את התמונה, שווה להכיר גם את ה Universal Scalability Law (בקיצור USL) שמפרמל מהי מקביליות, וממנו ניתן לראות שניסיון לדחוף יותר עבודה מקיבולת מסויימת – דווקא תאט את המערכת עוד יותר.
מודל המקביליות של InnoDB
לב מודל המקביליות של InnoDB, בדומה לבסיסי-נתונים רבים אחרים, מבוסס על שני כלים עיקריים:
נעילה פסימיסטית – לקיחת מנעול על משאב (טבלה, רשומה, וכו') בצורה שתגביל פעולות מקביליות אחרות – אך תמנע בעיות של עקביות-נתונים.
מחלקים את הנעילות ל-2 סוגים:
נעילה משותפת (Shared lock) עבור פעולות קריאה. אני קורא ערך ואוסר על שינוי הערך – אבל לא יפריע לי שטרנזקציות נוספות יקראו את הערך גם.
נעילה בלעדית (Exclusion lock) – לצורך שינוי הערך. אני תופס את המנעול, ולא אתן לשום טרנזקציה אחרת אפילו לקרוא את הערך (כי הוא עומד להשתנות)
נעילה אופטימיסטית – מאפשרת לתת לפעולות לרוץ במקביל, לגלות "התנגשויות" ואז להתמודד איתן.
לפעמים נרצה להכשיל את אחת הטרנזקציות (או יותר – אם יש כמה). לפעמים נסכים לקבל חוסר אחידות בקוד.
למרות שיש עבודה משמעותית נוספת בגילוי וטיפול ב"התנגשויות", אנו מאפשרים מקביליות בין הפעולות – שזה יתרון שלא יסולא בפז (הציצו שוב בתרשים שלמעלה – כמה צמצום החלקים ה"בלעדיים" הוא חשוב).
מבחינת אלגוריתמים MySQL, בדומה לרוב בסיסי-הנתונים הרלציוניים משתמשים בשני אלגוריתמים עיקריים:
2PL (קיצור של Two-Phase Locking) עבור נעילה פסימיסטית. הרעיון הוא שנחלק את הפעולה לשני שלבים:
שלב ראשון – בו ניתן רק לתפוס מנעולים.
שלב שני – בו ניתן רק לשחרר מנעולים.
לרוב נרצה לתפוס מנעולים ע"פ סדר מסוים ("קודם אובייקט מסוג X ורק אז אובייקט מסוג Y") – על מנת להימנע מ deadlocks.
במקרים אחרים, אנו יכולים להחליט לתפוס בסדר לא-קבוע על מנת לצמצם זמני-נעילה ולהגביר מקביליות, במחיר שטרנזקציות יבוטלו לנו. המשמעות: נצטרך לפעמים לנסות להריץ אותן כמה ניסיונות – עד שנצליח לתפוס את המנעולים הרצויים.
MVCC (קיצור של Multi-version concurrency control) הרעיון שבו אני "מעתיק" הנתונים שטרנקזציה צריכה הצידה, ואז היא חיה ב״סביבה וירטואלית משלה״, ללא התעסקות ב racing conditions או צורך בנעילות.
במימוש של InnoDB, לא באמת מעתיקים נתונים, אלא משתמשים בעמודות טכנית של המערכת לכל טבלה, המנהלת איזה עותק של הנתונים שייך לכל טרנזציה, ואלו ערכים נמחקו.
כמובן שיש מחיר שנוסף בניהול "העותק הוירטואלי". למשל: כאשר טרנזקציה מבקשת ערך שבטיפול של טרנזקציה אחרת – על בסיס הנתונים לבצע הדמיה של rollback של הטרנזקציה האחרת על מנת לדעת אלו ערכים צריכים להיות לטרנזקציה הנוכחית.
למרות המחיר הנוסף בפעולות הללו – הוא אינו דורש בלעדיות ולכן scales well.
בעיות חוסר-עקביות
כל טרנזקציה ב MySQL היא, כברירת מחדל, ברמת הפרדה (Isolation Level) שנקראת Repeatable Read.
ישנן 4 רמות הפרדה שהוגדרו ע"י התקן ANSI-SQL 92 ומקובלות בכל בסיסי-הנתונים הרלציוניים המוכרים.
למרות שרמות ההפרדה והתופעות האפשריות[ב] הוגדרו בתקן ה ANSI-SQL – ההתנהגויות בין בסיסי-הנתונים עדיין מעט שונות.
למשל: SQL Server לא מגן בפני Phantom Reads ברמת הפרדה של Repeatable Read, אבל כן מגן בפני Write Skew או Lost Update. אורקל משתמש רק ב MVCC ולא ב 2PL, מה שתורם למקביליות – אבל גם אומר שרמת הפרדה של Serializable לא מגנה בפני Write Skew….
בקיצור: Tradeoffs. Tradeoffs everywhere.
רשימת התופעות הבעייתיות האפשריות:
Dirty Write – כאשר שתי טרנזקציות יכולות לשנות את אותו השדה, כך שטרנזקציה אחת משנה את הערך לשנייה.
בגלל השימוש ב MVCC (או גישה יותר מחמירה: 2PL) – זה לא יקרה אף פעם בטרנזקציה של MySQL.
Dirty Read – הטרנזקציה יכולה לקרוא שינוי של טרנזקציה אחרת שהוא עדיין לא committed. הערך הזה יכול להתבטל (rollback) מאוחר יותר – בעוד הטרנזקציה שלנו משתמשת בו. התוצאה עשויה להיות שנשתמש בערך שאין לו ייצוג תקין בשאר המערכת (למשל: id לרשומה שלא קיימת). לא משהו…
Not Repeatable Read (בקיצור: NRR) – הטרנזקציה קוראת ערך משדה x בנקודת זמן t1, וכאשר היא קוראת שוב את השדה הזה בנקודת זמן מאוחרת יותר, t2 – ערך השדה הוא שונה. כלומר: טרנזקציה אחרת עשתה commit (אולי autocommit) – והערך שאנו רואים איננו עקבי. ההתנהגות ה NRR שוברת את תמונת "העולם המבודד" שרצינו ליצור לטרנזקציה שלנו – ובמקרים רבים היא יכולה להיות בעייתית.
Phantom Read – הטרנזקציה ביצעה קריאה של תנאי מסוים (נניח: year between 2016 and 2018) וקיבלה סדרה של רשומות, אך בינתיים טרנזקציה אחרת עשתה commit והוסיפה רשומות חדשות לטווח. כלומר: אם ניגש שוב לטווח – התוצאה תהיה שונה.
זו וריאציה מורכבת יותר של NRR. בעוד NRR ניתן לפתור בעזרת נעילה המאפשרת קריאות-בלבד מרשומה שאליה ניגשה הטרנזקציה, נעילה של טווח שנובע מפרדיקט היא דבר מסובך למדי – גם עבור בסיס נתונים משוכלל.
Read Skew – וריאציה נוספת של NRR: ישנן 2 טבלאות עם קשר לוגי ביניהן. שדה x באחת משפיע או מושפע על שדה y בטבלה השנייה. הטרנזקציה קוראת ערך x מטבלה אחת, אך בינתיים טרנזקציה אחרת משנה את x וגם את y (בצורה עקבית). בסיס הנתונים לא יודע בוודאות על הקשר, וכאשר אנו קוראים את y – עדיין עלולים לקבל את הערך הישן – לפני העדכון של הטרנזקציה השנייה. התסריט הזה מעט מבלבל – הנה דוגמה מפורטת.
Write Skew – וריאציה דומה, בה שתי טרנזקציות קוראות את שני הערכים x ו y, ואז אחת מעדכנת את x – בעוד השנייה מעדכנת את y. התוצאה – עקביות הנתונים נשברה. הלינק מלמעלה מספק גם דוגמה מפורטת ל Write skew.
Lost update – שתי טרנזקציות קוראות ערך ומעדכנות אותו. אחד העדכונים יאבד – מבלי שנדע שכך אכן קרה. במקרה של counter, למשל – הנזק מוחשי מאוד. גם בשדות המכילים ריבוי פריטים (כמו json) – הנזק הוא ברור. ישנם גם מקרים נוספים בהם התוצאה היא בעייתית.
למרות ההגנה הרבה שהן מספקות, חשוב לנסות ולהימנע מרמת הפרדה של Serializable – היכולה לפגוע משמעותית במקביליות, במיוחד כאשר הטרנזקציות אינן קצרות.
חזרה לתסריטים מתחילת הפוסט
פתחתי בכמה תסריטים מהניסיון היום-יומי שלי. בואו ננסה להתאים לכל אחד את הרמת ההפרדה המינימלית המספקת.
אם רק מעניינת אותנו היכולת לבצע מספר פעולות ביחד, או שאף אחת לא תתרחש (rollback) – ואנו מוכנים לקבל חוסר-עקביות כאלו ואחרים הנובעים ממקביליות (כמו עבודה רגילה בבסיס נתונים, ללא טרנזקציות), אזי רמת הפרדה של Read Uncommitted מספיקה לנו – ותספק מקביליות טובה.
מניסיוני, שימוש בטרנזקציות פעמים רבות בא לפתור רק בעיה זו, בעוד אנו מוכנים לקבל אי-עקביות הנובעת ממקביליות של פעולות.
אם מדובר בנתונים להם יש גישות רבות – שקלו ברצינות להשתמש ברמת הפרדה של Read Uncommitted או Read committed. חשוב לציין שההבדל בהשפעה על המקביליות בין שתי הרמות הוא לא גבוה – ולכן הרבה פעמים אנשים בוחרים להשתמש ב Read Committed בכל מקרה.
אם מעוניינים ב Atomicity, היכולת של טרנזקציה להתבטל מבלי להשאיר "שאריות" אחריה בפעולת Rollback, אזי רמת ההפרדה של Read Committed עשויה להספיק – ולאפשר מקביליות רבה.
כאשר אנו רוצים להתגונן בפני Racing condition אפשרי (למשל: מתעסקים בדברים רגישים, כמו כסף או פעולות שיש לדייק בהן) – אזי לרוב נרצה להשתמש ברמת הפרדה של Repeatable Read.
כאשר אנו רוצים ששאילתות יפעלו, לוגית, בזו אחר זו ללא מקביליות, למשל: תסריט שבו אנו משתמשים בבסיס הנתונים לסנכרון השרתים – הרמה המתאימה היא כנראה Serializable. חשוב להבין שרמה זו באמת חוסמת גישה מקבילית מכל-סוג לנתונים, ואם זקוקים לגישות רבות – תתכן פה פגיעה רבה בביצועים.
בשתי הדוגמאות האחרונות, אם אנו יודעים בוודאות שהגישה הקריטית היא רק לרשומה בודדת (למשל: קריאת ערך – ואז עדכון) – אזי Read committed היא רמה מספיק טובה. כל הרמות הגבוהות יותר מגינות מפני תסריטים של ריבוי רשומות / טבלאות.
עם אופטימיזציות כאלו כדאי להיות זהירים: משהו עשוי להשתנות בתוכן הטרנזצקיה, מבלי שמבצע השינוי יזכור / יבין שעליו להעלות את רמת ההפרדה.
מצד שני, יש כמה יתרונות משמעותיים לשימוש ב Read Committed (בקיצור RC) על פני Repeatable Read (בקיצור RR) מבחינת ביצועים:
ב RR, מנוע InnoDB ינעל כל רשומת אינדקס ששימשה את הטרנזקציה. אם חיפוש הרשימה מתבצע באינדקס לא יעיל (סריקה של הרבה רשומות) – אזי חסמנו הרבה מקביליות.
ב RR, המנוע מחזיק את כל הנעילות עד סוף הטרנזקציה. ככל שהטרנזקציה ארוכה יותר – כך זה בעייתי יותר.
ב RR, המנוע יוצר gap lock, על רשומות באינדקס שעלו בטווח של השאילתה (גם אם לא נסרקו). שוב – נעילה שעשויה להיות משמעותית למקביליות. נדבר על gap lock בחלק השני של הפוסט.
הנעילות על האינדקסים הן דוגמה למצב בו טרנזקציה אחת מאיטה פעולות אחרות בבסיס הנתונים, שלא ניגשים לאותן הרשומות. הנה דוגמה נוספת (history length).
עוד שני תסריטים שציינתי ולא כיסינו הם אלו:
שיפור ביצועים – זה מקרה ייחודי – אך שימושי.
InnoDB מחזיק binary log, על כל שינוי שבוצע בינתיים עבור התאוששות מהתרסקות ועבור replications. כדי לשמור על הלוג ככשיר להתאוששות, עליו לבצע flush ללוג (כלומר: לדיסק) על כל טרנזקציה שמתבצעת.
אם אנו מבצעים עשרות או מאות שינויים (למשל: הכנסה של רשומות חדשות), בשל ה autocommit – אנו נחייב את המנוע לבצע עשרות או מאות flushes לדיסק (פעולה יקרה).
שימוש בטרנזקציה (הכי פשוטה) – יאפשר לבסיס הנתונים לבצע flush יחיד.
ביצוע שינוי בנתונים בצורה זהירה ומפוקחת – למשל: אנחנו מבצעים תיקון של נתונים היסטוריים בבסיס-הנתונים על פרודקשיין. אנחנו רוצים להימנע מטעויות בשאילתה (למשל: UPDATE ללא WHERE יעדכן את כל הרשומות – מבלי שהתכוונו) שיכולות לגרום לאסונות קטנים וגדולים.
כדאי מאוד, לבצע כל שינוי כזה בטרנזקציה. קודם להחיל את השינויים – ואז לבצע שאילתות שמאשרות שהתוצאה היא כפי שרצינו. אם זה לא המצב – אפשר לעשות מיד Rollback ולהתחיל מהתחלה.
בד"כ נשתמש ברמת Repeatable Read לכאלו שינויים. כבני-אדם, אנו נחזיק את הטרנזקציה פתוחה לנצח (דקות? יותר?) – ולכן כדאי להימנע מ Serialization – במידת האפשר.
כיסינו תסריטים נפוצים – אך הם לא מכסים את כל המקרים. לפעמים נרצה תסריט מעורב:
רוב הטרנזקציה זקוקה רק לאטומיות, אבל חלק קצר בה או משאב מסוים – דורש הגנה חזקה יותר.
אולי אנו רוצים התנהגות של Serialization – אך רק על פריט מידע קריטי אחד.
ככל שהטרנזקציה ארוכה ומורכבת יותר – כך ייתכן יותר שנזדקק ל"התערבות ידנית".
כיצד עושים "התערבות ידנית"?
אלו מנגנוני-נעילה נוספים, הרצים מ"אחורי-הקלעים", קיימים ב InnoDB? (למשל: הזכרנו את ה gap lock)
כיצד מאתרים בעיות של נעילות בעייתיות / עודפות?
[א] החל מחודש ספטמבר, נהוג כבר להתמקד רק בטכנולוגיות השנה הבאה. #שנה_נוכחית_זה_פח
[ב] התקן המקורי של ANSI-SQL 92 זיהה רק 3 תופעות אפשריות של חוסר עקביות בנתונים, אך מאמר שהגיע שלוש שנים אחריו, הציף עוד 4 מקרים בעייתיים נוספים.
[ג] בעצם, בסיסי-נתונים לא רלציוניים היו תמיד: היררכיים (קדמו, והתחרו עם בסיסי-נתונים רלציוניים – תקופה מסוימת), Time series, מבוססי-אובייקטים, מבוססי-XML, גיאוגרפיים, ועוד.
הם פשוט לרוב נשארו נישה, ולא הצליחו לייצר רעש, כמו הגל האחרון.