
(מוזר: וויקיפדיה בעברית טוען שהיו מוניות עוד ברומא העתיקה עם מונה מכאני – לא מצאתי לכך סימוכין אחרים, אז אני מניח שזו טעות תרגום כלשהי).
"שנייה אחת!" אתם עלולים לתהות, "מה קורה פה?".
האם האקרים מ השתלטו על בלוג ארכיטקטורת תוכנה ושתלו בו סיפורים על … מוניות?! מה הקשר?
צודקים! אני אסביר:
אחד מסוגי הידע החשובים והשימושים הוא Domain Knowledge, הבנת העסק: לקוחות, מתחרים, ספקים, תחרות, ממה מרוויחים, ממה מפסידים, מהם כללי המשחק של השוק וכו'. כל עסק – וה Domain Knowledge שלו. ההבנה הזו עוזרת לנו לבנות מערכות שמתאימות יותר לצרכים של ה Domain.
החלטתי, לקראת השנה החדשה, לעשות שינוי קריירה ולעבור מ SAP (חברת ענק לתוכנה עסקית), לחברה קטנה ומקומית – "תביא-מונית" (כלומר: GetTaxi). אני עוד ארצה לספר על המעבר בעתיד.
באופן משעשע, אגב, אני נתקל ביותר אנשים שמכירים את השם GetTaxi מאשר אלו שמכירים את השם SAP. "מאיפה אתה עובר?" – כבר שאלו אותי. SAP היא חברה גדולה פי 300 בערך, ובעלת-ברית צמודה של רוב ארגוני-הענק בעולם. קצת מוזר שהיא מוכרת פחות.
מוניות? אני? אכן אין לי מושג ב"ביזנס" של GetTaxi, ולכן החלטתי להשקיע מעט וללמוד. אם זה לא מעניין אתכם בכלל – לא אעלב אם תפסיקו לקרוא ברגע זה. כתיבת הפוסט – מסייעתי לי לקרוא ולחקור את המקורות מהם אני לומד (קישורים שמצאתי בגוגל). יש גם ייתרון נוסף: כרגע, אני יכול עוד לפרסם את המידע ללא חשש לפגיעה ב GetTaxi – כי אני באמת לא יודע עדיין שום דבר מהותי שאוכל להסגיר. הפוסט, כמובן, הוא דיי בסיסי. אני מניח שאחזור לקרוא את הפוסט עוד שנה-שנתיים, וזו תהיה חוויה משעשעת.
עבורכם הקוראים, אני חושב זה עשוי להיות תרגיל מעניין לראות איך נראה Domain Knowledge של תחום אחר. האם יש דברים שמסקרנים אותכם, בתחום שלכם, לאחר שקראתם את מה שכתבתי שאתם עוד לא יודעים?
אם יש לכם מה להוסיף ולהעיר – רק אשמח על כך!

המונית כ"עסק"
איך אדם נהייה "נהג מונית"?
לנהיגה במונית, ראשית כל זקוקים לרשיון נהיגה D1 (דרגה 5) שניתן לאחר שעוברים קורס מטעם משרד התחבורה שאורך כחודש. בקורס מלמדים, אגב, מעט אנגלית (רק קצת!), ידיעת הארץ, עזרה ראשונה וכו'.
מונית היא גם עיסוק (נהיגה) וגם עסק (הפעלת מונית). הרבה פעמים הנהג הוא גם בעל העסק, אבל יכול להיות בעל עסק שמחזיק בכמה מוניות – אך הוא לא נוהג בעצמו.
רשיון להפעלת מונית (שייך לבעל המונית, שהוא לא בהכרח הנהג) נקרא בסלנג "מספר ירוק" – על שם הלוחיות הרישוי הירוקות שהיו למוניות בימי המנדט הבריטי. ניתן להוציא "מספר ירוק" בתהליך בירוקרטי או לרכוש אותו, במחיר נמוך מעט יותר, מבעל "מספר ירוק" אחר שמוכן למכור. מחיר השוק כרגע עומד על כ 230-240 אלף ש"ח (ע"פ נהג מונית שנסעתי איתו), כ 10,000 ש"ח פחות מהמחיר של מספר חדש בתהליך הבירוקרטי.
בכדי להתפרנס, הנהג זקוק לנוסעים, אותם הוא יכול להשיג ב-2 דרכים עיקריות:
- "להסתובב" במקומות הומים בתקווה שמישהו ירים יד ויזמין מונית.
- הצטרפות לתחנת מוניות, שמאפשרת לו לקבל הזמנות בנוסף לנוסעים מזדמנים. החברות בתחנת מוניות עולה כ 1000-1500 ש"ח בחודש, ובתמורה הנהג מקבל יותר הזדמנויות הסעה.
עד שנת 1998 מספרם של "המספרים הירוקים" הוגבל ע"י מכסה שנוהלה ע"י משרד התחבורה – מה שהגן על נהגי המוניות בפני תחרות משמעותית וחדשה. בכדי לשפר את השירות לאזרח, ובהתבסס על מחקרים שהראו ששוק המוניות לא נפגע מכזה מהלך (כי יותר מוניות זמינות = יותר לקוחות שמשתמשים בשירות) החליט המשרד לבצע רפורמה (סוג של "כבישים פתוחים") ולפתוח את שוק המוניות לתחרות.
מכשיר ה GPS, שהפך לנפוץ מעט אח"כ, הסיר את חסמי הכניסה המעשיים של נהגי המונית: התמצאות ברחובות העיר. מסתבר שזו יכולת לא כ"כ פשוטה שמפתחת באופן ברור אזורים מסוימים במוח. הסרת החסמים אפשרה כמעט לכל מי שרוצה – להפוך לנהג מונית, "פרנסת מפלט למובטלים", היו שאמרו.
בתוך מספר שנים הוכפל מספר המוניות בארץ מ 9,000 עד לכ 20,000 מוניות. כ 90% מהמוניות הן מוניות "ספיישל" – והשאר מוניות גדולות יותר (מוניות שירות, בעיקר. מקור).
הגדלת ההיצע, הגבירה את התחרות. המחירים ירדו, וזמינות המוניות עלה (מה שטוב לצרכנים) – אך בד בבד הפחית משמעותית את ההכנסות של נהגי המוניות. המשכורות ירדו, וגרמו להגברת התחרות בין הנהגים, ואיתה עלו שעות העבודה שהם משקיעים. ע"פ כמה מקורות (1, 2) – משכורת ריאלית של נהג היא בין 5000 ל 10000 ש"ח בחודש (נטו), כאשר המשכורות גבוהות יותר במרכז (ת"א). נהגי המוניות גם מספרים שת"א היא סביבת עבודה נוחה יתר עבורם – והסטנדרט המקובל הוא לנסוע עם מונה, בעוד שבב"ש ובחיפה למשל, מקובל להתמקח עם הנהג על המחיר לפני הנסיעה (מחיר שיהיה זול יותר).
מעבר למגמות הארציות, שהפכו את המקצוע לקשה יותר, יש גם "אירועים מקומיים" שיכולים להשפיע על השוק. למשל, בשנה האחרונה החלה עיריית חיפה בהפעלת המטרונית – מערכת אוטובוסים בצירים מרכזיים בעיר. התשלום מתבצע באופן עצמי במכונה (ולא אצל הנהג), והשמועות אומרות שרבים מהנוסעים "שוכחים לשלם". שירות משופר זה של העירייה, פגע כמובן בנהגי המוניות – שהתושבים זקוקים פחות לשירותיהם. ישנה תופעה של נהגי מונית שנוסעים עד ת"א בכדי למצוא פרנסה ("הרס את העיר הזאת, ראש העיר" – סיפר לי נהג אחד).
קטע מתוך האתר של משרד התחבורה, נובמבר 2013:
הרפורמה בתעריפים
כדי לסייע במשבר הכלכלי הפוקד את המוניות המיוחדות בשנים האחרונות, נערכת רפורמה במבנה התעריפים שלהן. הרפורמה כוללת את העלאת תעריפי הנסיעה במקביל לעליית המדד, שינוי תעריפי הנסיעה בעת נסיעה בפקקי תנועה ותוספת מחיר לנסיעה מיוחדת שבה נוסעים למעלה משלושה נוסעים. כמו כן, הותקנו מונים חדשים וניתנה אפשרות למוניות מיוחדות להשתתף במכרזים ברשויות מקומיות להסעת נוסעים. במוניות הותקן "מפתח לנהג" – התקן זיכרון אישי המתחבר למונה, מאפשר לזהות את הנהג וכולל תעריפי נסיעות בינעירוניות. מקור
חברת גט-טקסי (וחברות דומות) גם הם משנות את כללי המשחק: מערכת הקישור הממוחשבת בין נוסע-לנהג היא יעילה ומדויקת הרבה יותר מסדרן בתחנת מוניות. גודל החברה (גט-טקסי היא "תחנת המוניות" הגדולה בארץ, בהפרש ניכר) גם הוא מהווה יתרון משמעותי ביכולת לקשר בין נהג ונוסע שהם קרובים יותר. התייעלות מובנה זו שוב מצמצמת את מספר נהגי המונית הנדרשים בכדי לספק את הביקוש – ומגבירה את הלחץ על הנהגים שאינם חלק מהמערכת. תחנות המוניות הקיימות מתקשות להתחרות מול החברות החדשות ב 2 חזיתות מרכזיות: בטכנולוגיה (איגוד המוניות הוציא אפליקציה בשם Taxi To Go – לא נראית תחרותית במיוחד) ובשירות הלקוחות. במשך שנים, תודעת השירות בתחום הייתה דיי נמוכה.
היתרונות העיקריים של שירות כגון GetTaxi אותם מציינים לקוחות ברשת הם:
- המתנה קצרה יותר למונית. ניתן גם לתזמן את ההזמנה במדויק (כי אתם רואים כמה זמן ייקח לנהג להגיע).
- צמצום אי-הוודאות: ניתן לראות את המונית באפליקציה מגיעה, ומתי בדיוק היא מגיעה. לא עוד "המתנה באפס ידיעה" או "מונית שהזמנתם ופשוט לא הגיעה". אלמנט זה עשוי להיות משמעותי מאוד בזמנים לחוצים / לא נוחים.
- שירות לקוחות טוב יותר: גם מצד הנהגים, וגם מצד התחנה (גט-טקסי).
- יכולת לשלם באשראי, דרך האפליקציה: במידה ואין עליכם מזומן, אולי סתם יותר נוח לא להתעסק עם השלב הזה בנסיעה.
חברת אובר (Uber) איננה דומיננטית כ"א בארץ, אך היא משמעותית מאוד בעולם – הולכת צעד אחד קדימה ומאפשרת ממש לכל אדם עם רכב להירשם בזמן קצר שעומד בתנאים בסיסיים [א], ולצאת לדרך כנהג מונית – במשרה חלקית או במשרה מלאה. חברות נוספות (Lyft, SideCar) מציעות מודלים של "נהגים מזדמנים", המאפשרים הפחתה משמעותית של מחירי הנסיעה ב-2 דרכים עיקריות:
- אם אני נוסע, בכל מקרה, ממקום A למקום B, אני יכול לאסוף "נוסעים בתשלום" בדרך ולקבל החזר על חלק מההוצאות שהיו לי. כדאי לציין שרוב הפעילות של "נהגים מזדמנים" היא כשהנהג נמצא "באזור מסוים ויש לו זמן פנוי", ולא כחלק ממסלול מובנה.
- חלק מהנהגים המזדמנים לא עושים אומדן עלויות נכון (למשל אבדן ערך של הרכב, בלאי, זמנם שלהם) – ועובדים בעצם בתנאים גרועים למדי.
כמה נתונים מספריים על שוק המוניות בארץ (נתוני 2006):
- כ 40,000 נהגים (עובדים במשמרות על כ 20,000 מוניות).
- מחזור שנתי של 3.5 מיליארד ש"ח (כנראה 5 מיליארד בשנת 2014)
- כ 600,000 נסיעות ביום.
- כ 400 תחנות מוניות.

מודל כלכלי
כיצד נראה המודל הכלכלי של נהג מונית? מהן ההוצאות ומהן ההכנסות העיקריות?
מצאתי בגוגל כמה אומדנים כלכליים מפונפנים (דוגמה 1, דוגמה 2) – אבל הם לא היו עקביים אחד עם השני. חלק מהם העלו כמה הנחות לא סבירות (למשל: הוצאת דלק חודשית כ 1500 ש"ח, טוקבקיסטים אמרו שלפחות 4000 ש"ח).
משעשע לראות מודלים כלכליים המציגים דיוק לכאורה (סעיפים עם מספר לא עגול, למשל 1532 ש"ח ו16 אגורות) – תוך כדי שהם מפספסים את הדברים הגדולים (הוצאת הדלק היא בערך פי 3). "Precise, but not accurate" – למי שקרא את פוסט חנוכה השנה.
אנסה בכל זאת לתת תמונה כללית של המודל (לא Precise ואולי חצי Accurate), למיטב הבנתי:
הוצאות מרכזיות:
- עלות הרכב כ 100-200 אלף ש"ח לרכב חדש. כשרוכשים רכב שיהיה מונית לא צריך לשלם מכס ומע"מ (זו הוצאה מוכרת) – יש להוסיף אותם ביום בו מוכרים את הרכב לידיים פרטיות (וזה נהיה משתלם בערך אחרי 5 שנים – לאחר שהרכב איבד הרבה מערכו). שני הדגמים הנפוצים ביותר הם ב-2 קצוות המחירים המקובילים: סקודה אוטביה עולה כ 100,000 ש"ח, מרצדס כ 200,000 ש"ח (ללא מע"מ ומכס). נהגי המוניות היקרות משרתים בעיקר לקוחות עסקיים – היכן שאיכות הרכב יכולה להחזיר את ההוצאה.
בתחשיב חודשי של איבוד ערך הרכב + הוצאות מימון, מדובר בכ 2000-3000 ש"ח בחודש. - דלק תלוי כמובן בשימוש. יש תחנות שמגבילות את הנהגים שלהן ל 8-9 שעות עבודה ביממה, ויש נהגים שעובדים 12 שעות ביממה ויותר. נאמר 3000-5000 ש"ח בחודש (ללא מע"מ).
- ביטוח רכב (המחירים למוניות גבוהים יותר, כי הן נוסעות הרבה יותר) – כ 1000 ש"ח לחודש.
- שכירת מספר ירוק (מי שקונה חוסך קצת לאורך זמן) – כ 1000 ש"ח בחודר
- הוצאות שונות (תיקונים, טיפולים, ניהול חשבונות, קנסות, וכו') – כ 1000 ש"ח בחודש.
- חברות בתחנת מוניות – כ 1000-1500 ש"ח בחודש.

איפה הכסף?
אני לא יודע עדיין, בדיוק. נראה שחלק גדול מהפעילות הוא במגזר העסקי – שם פועלות כמעט ורק תחנות מוניות, ולא "חאפרים" (כפי שהחברים בתחנות אוהבים לקרוא להם. בעלי רישיון ו"מספר ירוק" – אך ללא תחנה).
הנה כתבה על רכבת ישראל שהוציאה כ 22 מיליון ש"ח בשנה על מוניות. "למה הם לא נוסעים … ברכבת?" זו אולי השאלה הראשונה, אך אם חברה אחת מוציאה סכום שכזה – כנראה שיש עוד הרבה כסף במגזר העסקי.
כשעסק שולח עובד למקום מסוים, כנראה שהוא מספק לו רכב או מונית. פשוט לא מקובל ברוב המקרים (ובצדק!) לבקש מהעובד לנסוע בתחבורה ציבורית. השירות לעסקים כולל כמה אקסטרות כמו שהנהג מתקשר כמה דקות לפני שהוא מגיע לטלפון של העובד, ומאפשר לבדוק היכן העובד (אם יש עיכובים).
משעשע לראות תחנות מוניות המסבירות את ההבדל בשרות לעסקים, כאשר הן מדגישות את המונח "טכנולוגיה לווינית" שוב ושוב (= GPS. אני מניח שזה תוכן שלא עודכן מספר שנים).
הכסף הגדול גם לא נמצא בארצות כמו ישראל – אלא בערי-הענק בהן צפיפות האוכלוסייה גדולה, והשימוש ברכבים פרטיים הוא קטן. למשל: בעיר ניו-יורק, יש 13,500 מוניות צהובות, שעושות כ 660,000 נסיעות ביום, על בסיס "הנפות יד". זה כמעט חצי מהמוניות בכל מדינת ישראל – שעושות את אותו נפח התעבורה כמעט, ללא כולל נסיעות מוזמנות מראש (מה קורה עם הזמנות של מוניות בעיר ניו-יורק – בהמשך).
הדרישה למוניות גוברת בצורה משמעותית בימים גשומים.
 |
| מתוך הסרט האלמותי "נהג מונית", עם רוברט דה-נירו. לא נהג המונית הטיפוסי. |
רמאויות
כולם מכירים את הסיפור על הנהג שעושה סיבובים על מנת להעלות את ערך הנסיעה.
אני לא יודע עד כמה הדבר באמת קורה, וכמה זה רק חשד של הנוסע, אולם עיריית NYC חייבה מוניות להתקין מסך עם המפה במושב האחורי – בכדי למנוע רמאויות אפשריות. אם אתם נוסעים עם אפליקציה (אני מכיר את החוויה של GetTaxi) – תוכלו לראות את מסלול הנסיעה על ה Smartphone שלכם.
עוד סיפורים על רמאויות כוללים לחצן סמוי של הנהג שמקפיץ את המונה (נהג ישתמש בטריק הלא-חוקי הזה מול נוסעים שנראים לא מפוקסים / שמפגינים אי-התמצאות באזור). טכניקות מסופרות אחרות הן לעשות את עצמם שהם לא מוצאים את היעד (ואז לעשות סיבובים), או להיכנס בכוונה לפקק רציני – מה שיבטיח להם תעריף גבוה יותר.
ברור שחלק מהעניין הוא נוסע חשדן, שהדרך נראית לו מוכרת ("סיבובים") או ארוכה ("יותר מדי זמן") והוא מסיק שמרמים אותו. בשעות שיש מספיק עבודה, משתלם יותר לנהג לעשות יותר נסיעות קצרות – מאשר לנסות ולהאריך אותן. עד כך לגבי המוטיבציה. נהגי מוניות מסוימים יבקשו מהנוסע לבחור באיזו דרך לנסוע – רק בכדי שלא יאשימו אותם בניסיון רמאות.
נהגים יודעים לספר גם על רמאויות של נוסעים: בעיקר כאלו ש"אין עליהם כסף" – עולים להביא ארנק, ואף פעם לא חוזרים. תופעה אחרת היא כאלו שסוגרים מחיר ליעד מסוים – ובעצם הם "התבלבלו", מכוונים את הנהג ליעד קצת יותר רחוק – ומצפים לאותו המחיר. יש גם נוסעים שפשוט נותנים לנהג להמתין הרבה (בתחילת הנסיעה, או בעצירה בדרך) – ומצפים שיעשה זאת כשירות ללא תשלום. מספרים ש"תרגילים" שכאלו מתרחשים יותר בפריפריה, מאשר בתל-אביב.
נראה ש GPS ורישום מדויק של הנסיעה – מצמצמים במידה רבה מקרים שכאלה (או סתם בעיות של חוסר אמון).
מוניות בעולם
מה ההבדל בין מוניות בארץ למוניות בשאר העולם?
בלונדון, למשל, כל המוניות נראות אותו הדבר. דגם הרכב שמשמש מוניות הוא דגם שנבנה באופן בלעדי לצורך זה (זהו ה Austin TX4, או דגמים קודמים שלו) – מה שהפך לסוג של אייקון.
לעיר ניו-יורק, יש אייקון משלה – המונית הצהובה. בפועל, יש ב NYC כ-3 סוגי מוניות: צהובות, שחורות, וירוקות (האחרונות הן חדשות יחסית, הן על הכביש קצת יותר משנה).
- מוניות צהובות (medallion taxis [ב]) – הן מוניות להן מותר רק לאסוף אנשים מהרחוב (ללא תיאום מראש), או מתחנות המוניות שיועדו לכך. מספרן מוגבל ע"י רגולציה. דגמי הרכב המשמשים את המוניות הצהובות, נמצאים כרגע בתהליך החלפה שיסתיים ב 2018 – והן יוחלפו לדגם של ניסן הדומה יותר למיניואן (בכדי לאפשר הסעה של נכים הנעזרים בכיסאות גלגלים).
- מוניות שחורות (livery או FHVs) – הן מוניות להזמנה מראש בלבד – ואסור להן לאסוף נוסעים אקראיים.
- מוניות ירוקות (ירוק-וואסבי) (SHL, נקראות גם boro) – הן כמו מוניות שחורות, אך שמותר להן גם לאסוף נוסעים – מהרחוב ה 110 (או 96 מזרח) וצפונה בלבד [ג]. זהו אזור דליל יחסית ב"נוסעים מזדמנים" – ושבעלי המוניות הצהובות לא ששים להסתובב בו. כרגע יש תהליך בו מאפשרים ליותר ויותר מהמוניות השחורות "להפוך" לירוקות.
הצבע הצהוב, אגב, נבחר בעקבות מחקר אקדמי שהראה שזהו צבע שבולט יותר לעין האנושית על רקע אפור (כמו מרקר – שהוא צהוב). הוא נפוץ לא רק בניו-יורק, אלא במדינות שונות ברחבי העולם.
סה"כ בכל מדינה / עיר – מגדירים דגמי מכוניות בהן ניתן להשתמש למוניות. בישראל, למשל, מותר להשתמש בכל מכונית שאינה "רכב ספורט".

מדינות שונות עברו, או עוברות, תהליך דומה לזה שקרה בישראל: בעלות על מונית הייתה מנוהלת ע"י המדינה – מה שהיטב עם בעלי המוניות. הבלעדיות הזו נפרצת גם ע"י רגולציה, וגם ע"י מודלים "עוקפי רגולציה" – מה שגורם לשינויים משמעותיים בשוק, עם "מרוויחים" ו"מפסידים". פעמים רבות למוניות יש איגוד או לובי – שמעכב, אולי מצמצם, אך לא מצליח למנוע, את השינויים שמתרחשים.
לכל מדינה יש רגולציות מעט שונות משלה, שיטות חישוב שונות לעלות הנסיעה, ומסים שונים. חברות בינלאומיות צריכות להתמודד עם המגוון הזה – אבל זה לא משהו ששונה מהותית מתחומים עסקיים שונים. המערכות של סאפ, למשל, הותאמו לרגולוציות שונות בעשרות מדינות שונות – מה שהפך אותן לכלי חיוני עבור חברות בין-לאומיות שפועלות במגוון המדינות הללו.
טיפים לנהג המונית הם דיי מקובלים בעולם, בתעריפים של 10% עד 20% (תלוי גם במדינה). במדינות שונות (נאמר, קנדה) אי מתן טיפ נחשבת כדרך בוטה להעביר מסר לנהג שלא הייתם מרוצים ממנו (ממש כמו במסעדות בישראל).
תחרות
ב 2007 יצאה אפליקציה לניהול נסיעות במונית (מן organizer אישי) בשם RideCharge, שאח"כ הפכה ב 2009 ל TaxiMagic שגם עוזרת להזמין מוניות (אפליקציה שמוכרת היום כ Curb).
השינוי הגדול היה בהופעת ה iPhone ומעט אחריו – בפתיחת ה AppStore, באמצע שנת 2008. כמה מהאפליקציות המוכרות הופיעו בסביבות שנת 2010 – זמן סביר להבין שיש ב iPhone פוטנציאל אמיתי + זמן פיתוח אפליקציה ראשונה.
האפליקציות שיצאו הן רבות ומגוונות, וחלקן עזרו לנוסע או לנהג. למשל: אפליקציה לניהול נסיעות (לנוסע), אפליקציות לביצוע התשלום בלבד (של Verifone ו CMT) או אפליקציות לנהגים, שעזרו להם לחזות באילו פינות רחובות לחכות – ע"מ לצמצם למינימום את זמן ההמתנה לנוסע הבא (CabSense).
האפליקציות שגרמו ל Impact הרב ביותר הן האפליקציות שקישרו בין נוסע-לנהג, וטיפלו בכמה שיותר נושאים מסביב לנסיעה (הזמנת המונית, תשלום, ניהול חשבוניות, רייטינג, וכו'). המרכזיות שבהן הן:
- GetTaxi – כמובן. גאווה ישראלית! (נקראת Gett בארה"ב, איני יודע למה). השירות מתמקד בנהגי מוניות מקצועיים.
- Uber – שצמחה מסן פרנסיסקו, "הגורילה" של התחום. החברה הגדולה ביותר, בפריסה הרחבה ביותר. מרכז הכובד שלה הוא "נהגים מזדמנים", אך היא גם מספקת שירותי מוניות "קלאסיים". החברה פעילה גם בישראל.
- Lyft – הוא גם שירות שמתמקד בנהגים מזדמנים ופעיל בערים רבות בארה"ב. ייחודיות של Lyft הוא ה "Lyft Line" – היכולת למצוא נוסעים מזדמנים אחרים בדרך, אותם ניתן להוסיף לנסיעה ולהוזיל עוד יותר את המחיר. יש פה מנגנון שמוזיל באופן מובנה את הנסיעה מבלי לרושש אף-אחד, אבל נראה שהוא עדיין לא הוכיח את עצמו כ "Game changer". חברת אובר הציגה לאחרונה שירות דומה בשם Uber Pool.
- Sidecar הוא שירות דומה לשניים האחרונים, אבל נותן יותר שליטה לנוסע לבחון ולבחור ממש את הנהג (ע"פ סטטיסטיקות, וכו'). גם הוא זמין בכמה ערים גדולות בארה"ב.
- Curb, לשעבר TaxiMagic, שהחלה מחברות הסליקה של תשלום המוניות (שהצליחו לעשות זאת בעמלה נמוכה יותר) היא ותיקה ועם פריסה רחבה של כ 60 ערים במדינות שונות (ארה"ב, UK, קנדה או מקסיקו). היא מתמקדת בנהגי מוניות מקצועיים. נחשב שירות זול ולא כ"כ איכותי.
- Easy Taxi – אפליקציה החלה לפעול בברזיל, והיום היא זמינה ב 26 מדינות (כולל ישראל). השירות מתמקד בנהגים מקצועיים.
- Hailo – צמחה בבריטניה, וזמינה בכמה ערים בעולם. השירות מתמקד בנהגים מקצועיים.
כמות האפליקציות, והקצב המהיר בו החברות הללו צומחות מעיד שיש פה שוק צומח ומשמעותי: גט-טקסי גייסה 150M$ לאחרונה, אובר גייסה 1.2B$ לפי שווי של 40B$ (חברה שהוקמה ב 2009 !!!) – כנראה הגיוס הגדול ביותר שהיה אי פעם, שלא דרך הבורסה.
מלבד ההבחנה בין עבודה עם נהגים מקצועיים, נהגים מזדמנים, או "גם וגם", יש שוני מהותי בין האפליקציות, בנקודת המבט "מיהו הלקוח?".
Uber ו Lyft, למשל, מתמקדות כמעט לגמרי בצד של הנוסע: הן לוחצות תדיר על הנהגים להוריד מחירים (יש להן תחרות לא-קלה בתחום הזה) ולשפר את השירות. נהג שקיבל תלונות של לקוחות ימצא את עצמו מהר "בחוץ", ורוב הפיצ'רים שלהן ממוקדות בנוסע. אובר למשל כותבת לנוסעים שלה "No need to Tip". סרטון ההדרכה לנהג – מבהיר מהר מאוד "מי הבוס".
גט-טקסי, למשל, היא דיי מאוזנת ומשקיעה הרבה מאוד גם בנהגים: פיצ'רים, שירותים, והתייחסות.
חברות המוניות שיצאו עם אפליקציות, בחרו באופן טבעי צד מאוד ברור – צד הנהג.
איזה מודל הוא נכון יותר? הזמן יגיד.
Uber
בתור הענקית בתחום – לאובר מגיעה התייחסות מיוחדת בפוסט.
אובר הוקמה ב 2009 ע"י Travis Kalanick, ה"פנים" של אובר, לו זו החברה השלישית שהקים, ביחד עם שותף בשם Garrett Camp, שמאז עבר להתמקד בחברה אחר בשם Expa.
אובר החלה כחברת Premium עם מוניות בקצה-הגבוה של הסקאלה, אבל בהדרגה החלה לנסות מודלים שונים. ב 2012 היא הקימה "סדנת חדשנות" בשיקגו (ה "Garage") – שם ניסתה רעיונות שונים: משאית גלידה אותה ניתן להזמין דרך האפליקציה, מונית שנראית כמו ה DeLorean מ"בחזרה לעתיד" – עבור מעריציה הסדרה, הזמנת מסוק (במחיר מתאים), וכו' וכו'.
העיר שיקגו נבחרה בגלל התחרות הרבה שיש בה בין המוניות, והמחירים הנמוכים המקובלים. "אם משהו עובד בשיקאגו – כנראה שבאמת יש לו פוטנציאל".
בעקבות תחרות קשה על המחירים, אובר "יצאה" מנישת מוניות-היוקרה, והציגה את ה UberTaxi (שיתוף פעולה עם נהגי מוניות מקומיים) וה UberX (מוניות זולות, רכבים שבישראל נחשבים "רגילים", אבל בארה"ב הם רכבים "זולים").
הניסוי שכנראה באמת הצליח הוא הניסיון לאפשר למשתמשי אובר "להפוך לנהגים" עם הרכבים הפרטיים שלהם – ומשם הם נכנסו למודל ה"נהגים המזדמנים".
במקביל החברה צמחה והתפרסה ברחבי העולם: פאריס, טורונטו, סידני, לונדון, NYC, סינגפור, סיאול, ועוד.
גוגל היא אחת המשקיעות של אובר, ולאחרונה שילבה את היכולת להזמין מונית של אובר דרך שירותי המפות שלה.
Baidu, מנוע החיפוש הגדול בסין גם הוא ביצע השקעה משמעותית בחברה. בכל זאת, אובר נתקלת בקשיים בסין מצד הממשלה, שמנסה לסייע לשחקניות המקומיות המרכזיות: חברות בשם Kuaidi ו Didi.
בעיתונות אובר מוזכרת לפעמים כ"חברת Data Science", כנראה בעיקר מתוך אי-היכולת של העיתונאים להתמודד עם המושג הנשגב.
מודל כלכלי
ההכנסות העיקריות (כנראה?) של אובר הן מ 20% עמלה שהיא לוקחת מהנהגים על כל נסיעה. בנוסף יש תשלום שבועי של 10$ מכל נהג "לכיסוי הוצאות התפעול של אובר".
לאובר יש אלגוריתם (surge pricing) שמגביה בזמן אמת את תעריפי הנסיעות כאשר הדרישה למוניות היא גבוהה במיוחד (בוקר, גשם, או סילבסטר) וכך מאזן במידה גם את העומס: היכולת "לעשות מכה" מעודדת נהגים מזדמנים להיות זמינים בשעות העומס – וכך לספק את הביקוש. הפי'צר הזה אינו זוכה לאהדה רבה מצד המשתמשים, במיוחד כאשר מחיר הנסיעה יכול להעלות עד פי 7 יותר (מה שקרה בסילבסטר של 2011) מהמחיר הרגיל. אובר הגיבה לתלונות בכך שהיא "משנה את כללי המשחק בתחבורה – והיא מבינה שייקח זמן לאנשים להתרגל". האמת: זה לא דמיוני (חשבו על הנתיב המהיר של כביש י-ם – ת"א).
אובר מתפעלת צוות שעוקב אחר אירועים בעיר (כנסים, פסטיבלים, הופעות) – ומתזמן את המוניות "להיות בסביבה".
אובר לא מציעה, עדיין, יכולת להזמין מראש מונית לשעה מסויימת.
ביקורת
אם יש משהו שלא חסר לאובר (חוץ ממימון, אולי) – הוא ביקורת.
- צעדים שאובר עשתה מול הנהגים שלה (הכנסת מוניות זולות, העלאת העמלה מ 5% ל 20%, הוספת עלות שבועית לנהגים) – גרמה למרמור רב בקרב הנהגים.
- אובר זכתה להפגנות שונות ברחבי העולם (פריס, לונדון, וכו'), מידי נהגי-מונית שהיא ניסתה לחדור לערים שלהם. הטיעון העיקרי הוא שאובר מציבה תחרות לא הוגנת, כי השירות שלה שקול למוניות, אך היא לא משלמת מסים והתרים כמו נהגי המוניות הרגילים, ואינה נדרשת להכשרות / ביטוח שקול.
- בישראל, אובר הפעילה נסיעות בחינם במשך 48 שעות (בכדי לעורר תיאבון לשירות בקרב התושבים + כי אסור ל"נהגים מזדמנים" להסיע בתשלום) – צעד שלא בנה אמון בקרב הנהגים ("אם יאושר מודל אובר, תהיה אינתיפדה").
- אובר נמצאת בתסבוכות עם הרגולציה ברחבי העולם, מטעמים שונים (תרשים):
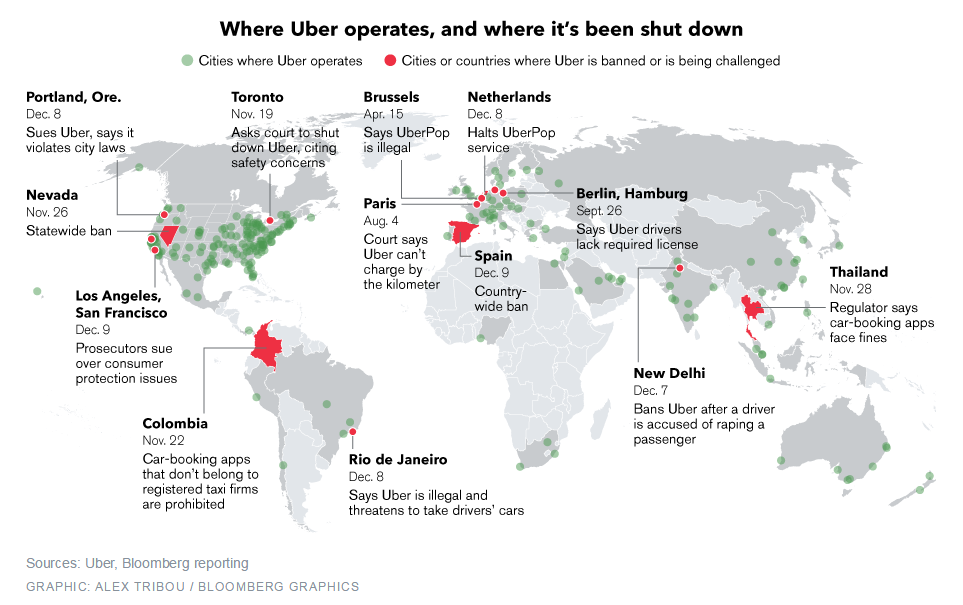
- אנשי מכירות של אובר הזמינו מוניות של גט-טקסי בניו-יורק, ואז ביטלו את הנסיעות. כך הם השיגו טלפונים של נהגי גט-טקסי, אותם הם ניסו לשדל לעבור לאובר, אבל תוך כדי כך הם גם הפריעו לשירות התקין של גט-טקסי, בצורת התקפת Denial Of Service (פשוטה, אך שעבדה). פעולה זו עוררה גלים באינטרנט וזכתה לפרסום גם באתרים כגון TheVerge או TechCrunch.
את אותו התרגיל הם עשו גם ל Lyft, כבר כמה פעמים. המהלכים נגד Lyft היו מכוונים ומצאו תיעוד שלהם במה שנקרא באובר "Operation SLOG". - אובר הואשמה גם באיום על עיתונאים, שימוש בכוחה למעקב אחר עיתונאים, אי שמירה על פרטיות משתמשיה, ושימוש באפליקציית האנדרואיד שלה באיסוף נתונים מוגזם על המשתמשים ("Uber's App is a malware").
- אובר אוהבת לטעון שהשירות שלה יפחית את מספר המכוניות שנמצאות על הכבישים – מצב שיכול לחסוך למדינות מיליארדים בתשתיות. טרוואיס קלאניק הכריז "making car ownership a thing of the past" והחברה אף הגדילה והציבה מספרים: "מיליון מכוניות פחות על כבישי לונדון עד סוף שנת 2014". קשה למדוד מה קרה בפועל, ספק אם מישהו באמת יודע, אך ע"פ סקר של פורבס, 90% מהמשתמשים הקבועים של אובר לא שוקלים בכלל לוותר על הרכב הפרטי שלהם, מה שמצביע על כך שהשינוי לא כאן. לפחות לא עדיין.
- אובר פרסמה נתונים שהמשכורת החציונית של נהג שלה הוא $90,766 בשנה. בתור חברה של "Data Science" ניתן להעריך שזה נתון מחושב ומדויק, אך עיתונאי שמסקר את אובר לא הצליח למצוא נהג יחיד שהגיע לסכום הזה. אובר עדכנה את הפרסומים שלה ל"אתה יכול להרוויח 70K$", אבל גם זה כנראה מספר לא מציאותי (ההערכות שאני מצאתי מדברות על 50K$).
 |
| מקור |
- אובר, למשל, מחשבת את זמן העבודה של הנהגים בצורה קצת מוזרה: להסיע לקוח או לנסוע לקראתו הוא זמן עבודה, אך זמינות והמתנה ללקוח הבא – אינו נחשב כזמן עבודה. האפליקציה לנהגים מציגה את שעות העבודה לפי החישוב של אובר – מה שמרגיז נהגים: היות וזמן העבודה ע"פ אובר יכול להיות נמוך ב 20% או יותר מזמן העבודה – כפי שהנהגים מבינים אותו (ובינינו: מאוד מקובל להבין. הדבר דומה לקופאית בסופר שלא סופרים לה זמן עבודה בזמן שאין מישהו בקופה…). התחשיבים של אובר גם הם מתייחסים ל"זמן העבודה נטו-נטו" – מה שמסביר חלקית את התחשיבים האופטימיסטיים שלהם.
- אובר איננה אהודה על הנהגים, ונהגים רבים נוטשים אותה לאחר שעבדו איתה זמן-מה. "תשעה מתוך 10 נהגים שדיברנו איתם מעדיפים לעבוד ב Lyft מאשר באובר".
- בכדי קצת לאזן: כנראה שאובר כן מציעה לחלק מהנהגים הכנסה גבוהה יותר מהאלטרנטיבות הקיימות.
 |
| גרף שנשלח ללקוחות UBER בברלין (בעיקר: נהגים), שעוזר להם לצפות את התנועה בליל הסלבטר. |
סיכום
קשה לבנות ידע ב Domain Knowledge בכמה ימים. קשה גם בזמן ארוך יותר: הידע בד"כ לא מאורגן או מסודר. אין ספרים, או הדרכות וידאו: יש לפעמים מחקרים או דוחו"ת – שמתמקדים בהיבט מאוד ספציפי של הפעילות, ולא מספקים תמונה מלאה ורחבה.
אני מקווה שכמה קוראים של הבלוג ימצאו את הפוסט מעניין – למרות שזה לא ה Domain שלהם. אם יש לכם הערות ותוספות – אנא אמרו! אני עוד לומד…
—–
הכבישים מוצפים בנהגים שאינם מומחים – דה מרקר, 2010.
העלמות מס, בהקשר לקשיים של ענף המוניות – גלובס, 2005.
| דרך המלך ל"מספר הירוק", 2012
מדוע מוניות הן צהובות (כלכליסט, 2015) Under Pressure From Uber, Taxi Medallion Prices Are Plummeting – עיתון ה NY Times, סוף 2014. |
—-
[א] ע"פ תשובה ב Quora התנאים הם:
- רכב 4 דלתות, שנת 2005 או חדש יותר
- מסמכים וביטוחים בתוקף
- נהג ללא הרשעות נהיגה ו/או פליליות
[ב] medallion הוא "המספר הירוק" בארה"ב.
[ג] הם שמו GPS במונה, והמונה פשוט לא יעבוד אם לא מדובר באזור "המותר".



















{kind=link}