- זה יכול להיות Waze – שאין סיכוי סביר לרוב החברות להקים מאגר / קהילה מקבילה.
- זה יכול להיות פייסבוק – שרשימת החברים שלי כבר מתוחזקת שם היטב.
- זה יכול להיות גוגל דרייב – שסתם אני רגיל ואוהב להשתמש בו.
אפילו אם תספקו למשתמש אותן סט יכולות באיכות מעולה – זה לא ישתווה לשירות אליו המשתמש רגיל.
!If you can't beat them – join them

צורות התחברות למערכת אחרת
אפליקציה מקומית – האפליקציה שלנו, לה אנו רוצים לעשות אינטגרציה למערכת אחרת.
אפליקציה מרוחקת – האפליקציה אליה אנו עושים את האינטגרציה.אציין את סגנונות האינטגרציה הנפוצות למערכות אחרות, מהקלה אל הכבדה:
אמנם נתתי דוגמאות של חיבור למערכות שכולנו מכירים (Waze, טוויטר, LinkedIn) – אך חלק גדול מהאינטגרציות שנעשות בעולם מתרחש בעולם ה Enterprise – שם יש אפליקציות משעממות כגון מעקב אחר פרויקט, ריכוז חיובים, וניהול זמינות של כ"א.
אינטגרציה של הפעלה (Invocation)
דוגמה לאינטגרציה: אני מחפש מסעדה באפליקציה של Rest, שפותחת מצידה ניווט של Waze ליעד.

ברוב הפעמים מערכת ההפעלה / סביבת ריצה מספקת את התשתית לאינטגרציה ומי שמעוניין באינטגרציה צריך:
- ללמוד את הפורמט/פרוטוקול להעברת context (למשל: כתובת לניווט) לאפליקציית היעד.
- (צעד רשות): לוודא שאכן האפליקציה השנייה זמינה (כי ניסיון להפעיל אותה מבלי שהיא זמינה – עלול להראות לא טוב).
דפוס חוזר של הפעלה של אפליקציה כזו הוא decoupling by intent:
- אני מבקש מאפליקציית ניווט כלשהי (ולא דווקא Waze) לענות לקריאתי – ושולח את הכתובת לסביבת הריצה שתמצא לי אפליקציה שיכולה לענות על כזו בקשה.
- סביבת הריצה מפעילה אלגוריתם החלטה (בד"כ: רשימת העדפות פשוטה) ומקשרת את ההודעה שלי לאפליקציה המתאימה ביותר (כלומר: הראשונה ברשימה).
פריט המידע שמועבר בין המערכת המקומית לאפליקציה המרוחקת עשוי, בתסריטים של Enterprise, להיות זיהוי של אובייקט עסקי – שאותו האפליקציה המרוחקת תוכל לערוך / לבצע עליו פעולות (על בסיס גישה משותפת של האפליקציות לבסיס הנתונים, או סוג של RESTful APIs).
מנגנון של decoupling המתבסס על כוונה (intent) מאפשר:
- להחליף את האפליקציית המרוחקת (בעולם המובייל היא מאוד קרובה, אך אדבק בטרמינולוגיה) – מבלי לשנות קוד / קונפיגורציה באפליקציית המקור.
- לאפשר התאמה אישית למשתמשים – לבחור באיזה "אפליקצייה מרוחקת" הם רוצים להשתמש (ולשמור במערכת את הבחירה).

אינטגרציה של נתונים (data integration) – מושגים בסיסיים
נוהגים לחלק אינטגרציה של נתונים ל 4 סגנונות עיקריים [א]:
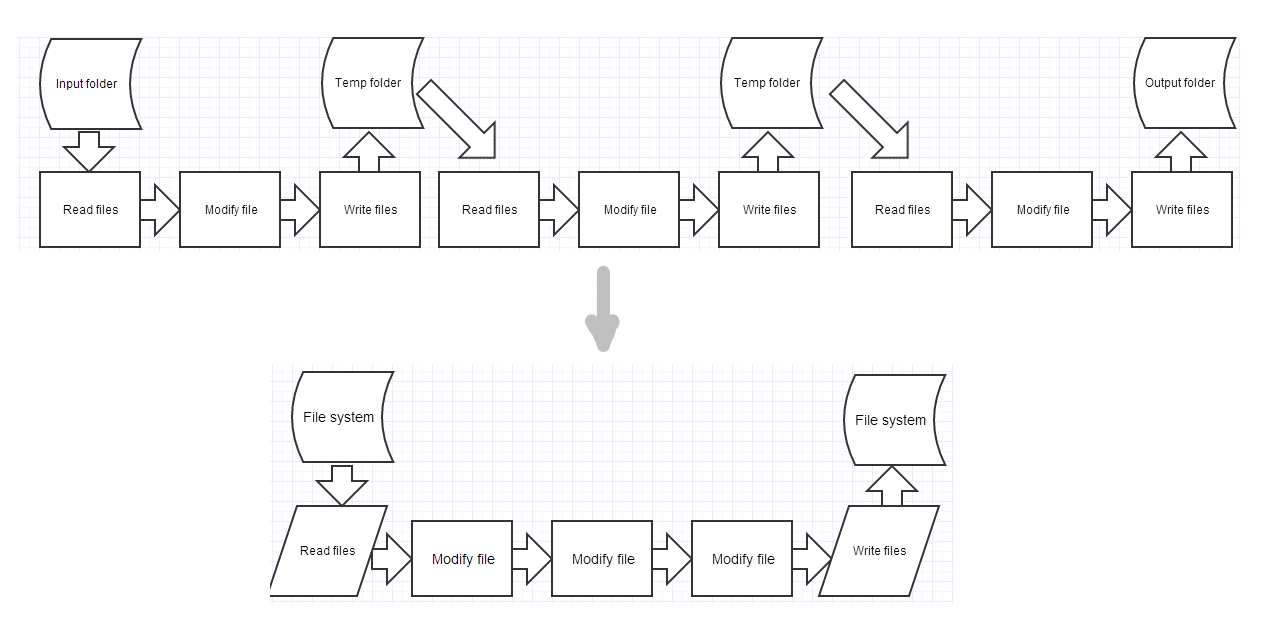
- אינטגרציה ע"י העברת נתונים בקובץ.
- אינטגרציה ע"י שיתוף בסיס נתונים.
- אינטגרציה ע"י קריאה מרוחקת (RPC).
- אינטגרציה ע"י שליחת הודעת (messaging / events-based).
- שכפול נתונים בין מערכות (Replication) או סנכרון נתונים בין מערכות. סנכרון זה מצב יותר בריא, בד"כ 🙂
- קיבוץ (Aggregation) נתונים ממקורות שונים למקום אחד – עבור דו"ח או Dashboard (לוח בקרה).
- הרכבה של תהליכים "עסקיים", הרכבת כמה אפליקציות פשוטות לאפליקציה מרוכבת ומועילה יותר (Business Processes). אני מדבר ב"שפה עסקית" אך זהו גם הסיפור של אפליקציית Rest שפותחת את WAZE שפותחת את גוגל (לקבל עוד נתונים בעקבות פרסומת בדרך).
- סיפוק שירותים נקודתיים, כדי למנוע שכפול נתונים או פונקציונליות – למשל שירות של מילון (Dictionary) או שירות קבלת כתובת דואר של עובד. שירותים אלו יכולים לשמש UI (כלומר: משתמש קצה) או מערכות אוטומטיות.
כן, אבל…
- אפשור גישה ברמת הרשת.
- עבודה בפורמטים שונים.
- אינטגרציה עם מערכות Legacy.
- אימות זהות ואבטחה.
- אנשים אחרים / עולם מושגים שונה / DNA ארגוני שונה.
- מערכות Legacy / שאינן יכולות להשתנות.
- הבדלי מהירות / קיבולת בין המערכות – שלא לדבר על זמינות.
- סינכרון ו Concurrency.
- שינויים ב API / חוזה (contract) של המערכת המרוחקת.
ספריות / מערכות אלו הן כלי עזר לאינטגרציה – אך לא "פתרונות קסם" ש"מסירים מהדרך" את הבעיות הנ"ל. למשל: במקום לכתוב 100 שורות קוד בכדי להאזין לשינויים בתיקיית קבצים, לפרסר את הקובץ ולשלוח את המידע החדש שנוסף כ JMS message – תוכלו אולי לכתוב בעזרת הספריה 4-5 שורות דקלרטיביות או ב DSL שיעשו אותה עבודה. בכל זאת, לא תמצאו שם פתרונות אוטומטיים לבעיות אבטחה, הבדלי מהירות או זמינות בין המערכות וכו'. בטח שלא לבעיות של תקשורת בין בני-אדם 🙂
יהיה עליכם להבין את האתגרים האפשריים, לחשוב, לנתח – ולפתור.
אפרופו יש קטגוריה של פתרונות בשם ESB (קיצור של Enterprise Service Bus) – שמופיעים כמודול ברוב פתרונות ה Middleware של החברות הגדולות (IBM, Oracle, TIBCO וכו') או בגרסאות חופשיות (למשל Apache Mule).
אלו בד"כ פתרונות יותר כבדים מ"מערכות האינטגרציה" אותן הזכרתי, הם קשורים בצורה הדוקה בד"כ לארכיטקטורת SOA שמרנית, ונחשבים כלא כ"כ מוצלחים (כקונספט – אני לא מדבר על המימוש).
אני לא מנסה לדבר עליהם, ולא רוצה שתבינו בטעות שכדי לבצע אינטגרציה – זקוקים לתשתית כלשהי. כלים שכאלו כדאי להכניס לשימוש כדי לחסוך זמן (במיוחד כשיש הרבה עבודה) – לא כדי "לפתור את הבעיה".

תהליך אינטגרציה: ממה להיזהר? וכיצד?
כל אחד מהנושאים ברשימת האתגרים למעלה יכול למלא (בקלות) פוסט שלם בעצמו. אנסה לספק מידע בסיסי על המשמעות של כל אתגר, ובשאיפה – מבלי לשעמם:
אנשים אחרים / עולם מושגים שונה / DNA ארגוני שונה
בסופו של דבר, זהו אולי הנושא הכי קשה, או לפחות שגוזל הכי הרבה זמן. ראיתי אינטגרציות בין צוותים באותה קבוצה – שהיו לא קלות. וראיתי אינטגרציות בין ארגונים+יבשות+מערכות+תפיסות עולם שונות – שארכו חודשים, שבאידאל יכלו לקחת ימים. ה"אידאל" הזה הוא מאוד תאורטי, כמעט אף-פעם לא קורה – ולכן עשוי להיות דיי מתסכל. כנראה שעדיף למחוק אותו מהלקסיקון ולא לנסות לעסוק בתאוריה של "כמה מהר / טוב ניתן היה לעשות את האינטגרציה אם אנחנו היינו גם בצד השני". עבודה עם קבוצה שונה מהותית מהקבוצה שלכם – עלולה להיות אתגר משמעותי בעת האינטגרציה.
כדי לא להפחיד יותר מדי: יש גם אינטגרציות קלות מבחינה זו. פעמים שבהם אתם נהנים לראות כמה מהר מבינים האנשים בצד השני במה מדובר, הם עושים עבודה טובה – שגם ניתן ללמוד דברים חדשים ממנה. גם זה יכול לקרות.
אפשור גישה ברמת הרשת
אם שתי המערכות המעבירות בניהן מידע נמצאות באותה רשת מקומית – אז אין בעיה.
במקרים אחרים הן נמצאות ברשתות שונות, שבניהן מותקנים רכיבי רשת מגבילים (חומות אש, IPS או אמצעי הגנה אחרים).
לפעמים מערכת אחת יושבת בענן, והשנייה ברשת הפנימית של ארגון (ואז יש שאלה איך ניגשים מהענן לרשת הפנימית).
לפעמים משתפים מידע בין 2 רשתות פנימיות של ארגונים שונים, שחוץ מחיבור זה – זרים זה לזה.
ענייני רשת – יש לפתור נקודתית למצב הנתון.
יש כלל מנחה שאומר שאת היוזמה לתקשורת עושים מהאזור המאובטח יותר – לאזור המאובטח פחות. כך יתר קל להתמודד עם אמצעי ההגנה השונים. למשל: מן הרשת הפנימית של הארגון – לענן, או מן הרשת הפנימית של ה Data Center לרשת הארגונית ה"רגילה".
במקרים בהם אין יכולת לתקשורת ישירה (בגלל מורכבות של רשתות ה LAN בארגון) – מציבים agent או broker בדרך שיאפשר להעביר הודעות / נתונים.
עבודה בפורמטים שונים
בעוד מערכת אחת עוטפת את המידע ב XML בצורה אחת – והשנייה ב XML בצורה אחרת. עצם השימוש "המשותף" ב XML לא מוסיף לאינטגרציה כמעט דבר, אם הפורמטים שונים. גם בתוך ה XML (או JSON, CSV וכו'):מערכת אחת מתארת תאריך בפורמט ארוך – והשנייה בפורמט קצר, אחת כתובת בשדה אחד והשנייה במספר שדות שונים, וכו'.
עבור קריאות מרוחקות (RPC), ההבדלים יכולים להיות גדולים יותר: DCOM מול CORBA או RMI מול REST API – צורת התקשורת שונה, ולא רק פורמט אותו ניתן להמיר.
יש גם נושא של Data Integrity: מערכת אחת מוכנה לקבל רשומה כאשר שדה x חסר (ערך ריק) – ומערכת שניה לא מוכנה לקבל זאת. אולי תאימות בין הנתונים: מערכת אחת בודקת את ערכי השדות שיתאימו לכלל מסוים – והשנייה לא.
את המידע ממירים בעזרת Adapters (או Transformers/Normalizars במערכת מורכבת יותר) – בכדי לתאם בין הפורמטים / פרוטוקולים. לפעמים עושים תהליך נוסף של Data Quality – תיקון הנתונים בכדי לעמוד ב"סטנדרטים" של אחד הצדדים (שלמות, דיוק וכו').
עניין של פורמטים הוא בד"כ לא "נושא מורכב" (זו קרקע מצוינת לכיסוי עם Unit Tests) – אך זו עבודה. בד"כ ככל שהמידע הוא Human Friendly – ההמרה תהיה קלה יותר. המרה של מידע בינארי, נוטה להיות מורכבת יותר.
אינטגרציה עם מערכות Legacy
בניגוד למה שהשם עשוי לרמוז, מערכות Legacy (לפחות בהקשר של דיון זה) הן לא דווקא מערכות ישנות – אלא מערכות שאבדה עליהן, במידה כזו או אחרת, השליטה. בהקצנה: מערכות שאין מי שיתחזק, יחקור ויבין – ואין שום סיכוי שמישהו יבצע בהן שינוי. יש מצבי ביניים בהם ניתן לבצע שינויים מסוימים.
ישנן מערכות בנות עשור או שניים – שעדיין נמצאות במצב של תחזוקה סבירה, ויש מערכות שהופכות למערכות Legacy ביום שבו שוחררה גרסתן הראשונה.
כאשר אנו רוצים לשלוף נתונים ממערכת Legacy שלא התאימה את עצמה ל export של המידע לו אנו זקוקים – משימת האינטגרציה יכולה להיות קשה. תת-תחום, מוכר יחסית, של נושא זה הוא העולם של Web Scrapping– שליפת נתונים ממערכות ע"י פענוח ה HTML שהן מייצרות (ולא תמיד בהסכמתן). משימות של Scraping בדרך כלל יותר נוח לעשות בשפות דינאמיות עשירות בספריות לטיפול בטקסט כמו פייטון או רובי, אם כי יש מגוון רחב של ספריות. אפשרויות אחרות הן "דיג" של נתונים מתוך לוגים או קבצי נתונים שהמערכת מספקת – אך תוכננו לצורך אחר.
אימות זהות ואבטחה
בעולם הווב / Social יש היום את OAuth שמקל על המשימה – לשלוף נתונים בצורה מאובטחת ממערכת מרוחקת. בעולם ה Enterprise התמיכה ב OAuth היא עדיין מועטה.
כאשר משתמש מזניק (invocation) אפליקציה אחרת – נרצה לחסוך ממנו הקשה נוספת של משתמש/ססמה, בעזרת SSO. כנ"ל לגבי שליפת / עדכון נתונים. בהרכבה של תסריטים עסקיים מורכבים, ייתכן והמשתמש יפעיל כמה אפליקציות שונות בכמה דקות. הקלה של ססמה כל פעם – היא שוחקת ומכבידה.
הבדלי מהירות / קיבולת בין המערכות
להבהיר: כאשר כל ה threads שלנו תקועים – לא נותרים threads ב Pool לפעולות אחרות, ואז ייתכן שגם המערכת שלנו – נתקעת ולא מגיבה.כלומר: אי-זמינות של מערכות הוא מדבק, ויש לבנות מנגנונים (נקראים Circuit Breakers) למניעת הידבקות זו.
Circuit Breakers יכולים להופיע כמנגנונים האוכפים timeout קצר בניסיון לקריאה ממערכת מרוחקת.
יש כאלו שיזהו רצף של תקלות וימנעו ניסיונות תקשורת – עד אשר תהיה התערבות ידנית / מנגנון שמזהה התאוששות יפעל.
 |
| Circuit Breaker מתוך הפוסט של מרטין פאוולר בנושא. |
וריאציה אחרת היא בהבדלים במהירות או Scalability בין המערכות:
שינויים ב API / חוזה (contract) של המערכת המרוחקת
אפילו יותר מכך: לפעמים ה API (החלק המוצהר) נשאר כפי שהוא, אבל חלק אחר, לא מוצהר, ב contract משתנה: סדר פעולות, Exceptions שנזרקים או תופעות לוואי אחרות. כל אלו – יכולים לשבור את האינטגרציה ודורשים תחזוקה.
ישנם מקרים בהם השינויים הם תדירים מאוד (בעיקר מוצרים צעירים) – ואז התחזוקה היא מעמסה רצינית.

סגנונות אינטגרציה וכיצד הם מתמודדים עם האתגרים השונים
עכשיו, לאחר שהכרנו (בגדול) את האתגרים שבאינטגרציה בין מערכות, הייתי רוצה לחזור ולספק כמה שיקולים מנחים עבור הבחירה בין סגנונות האינטגרציה השונים:
- "מדלגת" על מגבלות של רשת או הרשאות. ה export/import וה transport נעשים עם הרשאות של משתמשים ספציפיים.
- פשוט למימוש
- תקורה של קריאת / פענוח קבצים – מכבידה על טיפול בכמויות גדולות באמת של נתונים.
- פער זמן בין export ל import
- מתאים להעברת נתונים ולא ל invocation / הפעלת פונקציות (חד-צדדי)
- כשאופציה זו נבחרת, היא בד"כ מיושמת בצורה לא-אוטומטית
יתרונות:
- קל למימוש
- יעיל מבחינת ביצועים (גישה ל raw data)
- Consistency (יחסי) של הנתונים
- אין הכמסה. מערכת אחת נוגעת במבנה נתונים של מערכת אחרת. ניתן לראות זאת כממשק מאוד מאוד רחב בין המערכות – וזו הסיבה העיקרית שגישה זו היא הכי-פחות מועדפת עלי באופן אישי, מכל הסגנונות. שינויי סכמה משפיעים מיידית על 2 המערכות.
- גישה ישירה לבסיס הנתונים עוקפת Business Logic ואימות נתונים שבא איתה, Caches של ORM או שכבות עליונות וכו'.
- בסיסי נתונים (רלציוניים בעיקר) הם מאותגרים scalability והוספת מערכת נוספת שעובדת על אותו בסיס נתונים יכולה להיות מגבילה / לדרוש שדרוג יקר של החומרה.
אינטגרציה ע"י קריאה מרוחקת (RPC)
RPC הוא קיצור של Remote Procedure Call (שם שמקורו היסטורי) והכוונה היא לכל הטכנולוגיות של הפעלת פונקציות מרחוק: REST, RMI, XML-RPC, אולי RPC ברמת מערכת ההפעלה ועוד.
יתרונות:
- הכמסה בין המערכות
- ממשק מוגדר היטב
- online
- תלות חזקה בין המערכות (ממשק + ידע על מיקום/כתובת המערכת המרוחקת)
- תקשורת סינכרונית בלבד
אינטגרציה ע"י שליחת הודעת (messaging / events-based).
שליחת הודעות נעשית בד"כ דרך מנגנון לשליחת הודעות ייעודי, מה שנקרא MOM (קיצור של Message Oriented Middleware). מערכות נפוצות שבשימוש הן Apache ActiveMQ, RabbitMQ, רדיס (Redis) ומנגנון ה Pub-Sub שלו (עליו כתבתי בפוסט בעבר), Apache Kafka (ל Scale גבוה) או מימושים שונים של מנועי JEE/חברות התוכנה הגדולות.
יתרונות:
- גמישות רבה לאינטגרציות מורכבות
- פוטנציאל Scalability נהדר (בכמות הנתונים)
- אפשרות לאסינכרוניות ו reliable messaging (אולי תכונות חשובות, לא דווקא יתרונות)
- תוואי רשת יכול להקשות על scalability במספר המערכות המעורבות באינטגרציה
- איתור תקלות יכול להיות מורכב ודורש לוגים / כלי Monitoring
- פרגמנטציה רבה של תשתיות זמינות
סה"כ, לכל סגנון יכול להיות שימוש – ואין מניעה להרכיב כמה סגנונות שונים ביחד. סגנונות האינטגרציה הנפוצים כיום (כי שאני נתקל בהן) הן מבוססות קבצים (למשימות פשוטות) או מבוססות messaging (למשימות המורכבות/כאשר יש עניינים של scalability).